Bridging Worlds: How Diffusion Models Are Reshaping Language Generation
Exploring the revolutionary convergence of diffusion techniques with language modeling
The Evolution of Generative AI Paradigms
The landscape of generative AI has witnessed a fascinating dichotomy in recent years. While diffusion models have become the dominant force in generating perceptual content like images, audio, and video, language generation remains firmly in the grasp of autoregressive approaches. This division isn't arbitrary but stems from fundamental differences in how we represent and process different types of data.
The divergent evolution paths of generative AI across different domains
Autoregressive models became the standard for language modeling largely due to the discrete nature of text. These models generate text token by token, with each new token conditioned on all previous ones. This approach aligns naturally with how we read and write—sequentially, one word after another. Early successes with models like GPT (Generative Pre-trained Transformer) cemented this approach as the gold standard.
The conceptual gap between continuous data (like images) and discrete data (like text) represents the core challenge in applying diffusion techniques to language. Images exist in a continuous pixel space where subtle, gradual changes make sense. Text, however, lives in a discrete token space where the concept of "slightly changing" a word often has no meaning—a word either is or isn't present.
Timeline of Key Developments
The evolution from traditional language models to diffusion-based approaches
timeline
title Evolution of Language Generation Approaches
2018 : GPT-1 Released
: Autoregressive dominance begins
2020 : DDPM (Denoising Diffusion Probabilistic Models)
: Diffusion models gain traction in image generation
2021 : DALL-E and Stable Diffusion
: Diffusion dominates visual generation
2022 : First Experiments with Diffusion for Text
: CDCD (Continuous Diffusion for Categorical Data)
2023 : Large Language Diffusion Models (LLaDA)
: Embedding discrete data in Euclidean space
2024 : Hybrid Approaches Emerge
: Blending autoregressive and diffusion techniques
The timeline above illustrates how diffusion models evolved from primarily visual applications to increasingly sophisticated language applications. As researchers developed methods to bridge the continuous-discrete divide, we've seen promising approaches that apply diffusion techniques to language generation tasks, potentially challenging the autoregressive paradigm for the first time.
Understanding the Core Mechanisms
To appreciate the innovation behind diffusion language models, we must first understand how traditional diffusion models function with continuous data. Diffusion models work by gradually adding noise to data and then learning to reverse this process. For images, this means slowly transforming a clear picture into random noise, then training the model to reconstruct the original image from that noise.

The diffusion process applied to language data
Applying this same concept to language poses fundamental challenges. Unlike pixels in an image, words or tokens in language are discrete entities—you can't have "half a word" or gradually transform "cat" into "dog" through small, continuous changes. This discrete nature of language is the primary hurdle that diffusion language models must overcome.
Key Mathematical Frameworks
Continuous Diffusion for Categorical Data (CDCD)
This approach, pioneered by researchers at DeepMind, adapts diffusion models for language by treating discrete tokens in a continuous framework. CDCD aims to minimize the differences between training diffusion models and training traditional autoregressive models, making the transition more accessible to language modeling practitioners.
Latent Embedding Techniques
Rather than working directly with discrete tokens, these methods embed tokens into a continuous latent space. By applying diffusion in this continuous embedding space, models can avoid the pitfalls of directly applying noise to discrete tokens. This technique creates a bridge between the continuous nature of diffusion and the discrete nature of language.
Self-Conditioned Embedding Methods
These approaches use the model's own previous predictions to guide the generation process. By conditioning on its own outputs, the model can maintain coherence and semantic meaning throughout the generation process, even as it operates in a continuous space.
Comparative Analysis: Noise Addition and Denoising
How noise characteristics differ between image and text diffusion processes
The radar chart above highlights the key differences in how diffusion processes work across modalities. While image diffusion excels in noise granularity and multimodal compatibility, language diffusion models tend to better preserve semantic information and offer improved model interpretability. These trade-offs reflect the fundamental differences between continuous and discrete data domains.
Understanding these core mechanisms is essential for appreciating both the challenges and potential of diffusion language models. By addressing the discrete nature of language through innovative mathematical frameworks, researchers are gradually bridging the gap between these seemingly disparate approaches to generation.
Innovative Approaches to Diffusion Language Models
Recent breakthroughs in diffusion-based language modeling have demonstrated promising alternatives to the dominant autoregressive paradigm. These innovations primarily focus on solving the fundamental challenge of applying continuous diffusion processes to discrete language tokens.
Recent Breakthroughs
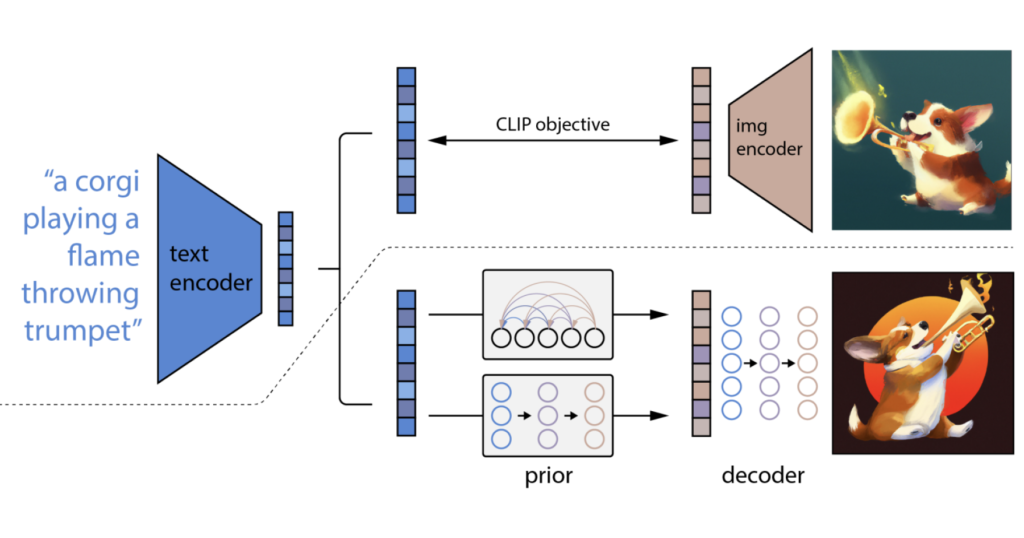
Embedding discrete language tokens into continuous Euclidean space
Embedding Discrete Data in Euclidean Space
Rather than abandoning the continuous formulation that makes diffusion models so powerful, researchers have developed methods to embed discrete language tokens into continuous Euclidean space. This approach preserves the advantages of continuous diffusion while adapting it for language. As noted by Sander Dieleman, this allows language models to retain useful features like classifier-free guidance and accelerated sampling algorithms that were developed for continuous diffusion models.
Large Language Diffusion Models (LLaDA)
LLaDA represents a novel architecture that applies diffusion directly to language modeling. Unlike approaches that attempt to adapt existing methods, LLaDA was designed from the ground up to leverage diffusion for language generation. This model demonstrates how diffusion can provide unique advantages for certain language tasks, particularly those requiring iterative refinement or controlled generation.
Latent Diffusion for Language
Building on the success of latent diffusion models in image generation, this approach applies similar principles to language. By operating in a compressed latent space rather than directly on tokens, these models achieve greater computational efficiency while maintaining generation quality. This technique views diffusion as complementary to existing pretrained language models rather than as a complete replacement.
Practical Implementations and Experiments
Real-world experiments with diffusion language models have demonstrated both their potential and current limitations. Several research teams have published implementations showing how diffusion models can generate coherent text, though often with different characteristics than text from autoregressive models.
One notable finding is that diffusion language models tend to excel at tasks requiring global coherence and structural consistency, as they generate the entire sequence holistically rather than token by token. This creates interesting trade-offs in model performance across different language tasks.
Performance Comparison
Benchmarking diffusion language models against traditional autoregressive approaches
The chart above highlights how diffusion language models compare to traditional autoregressive approaches across various performance metrics. While autoregressive models currently maintain advantages in text fluency and inference speed, diffusion models show promising results in global coherence and long-form structure—suggesting they may eventually complement or even surpass autoregressive approaches for specific language generation tasks.
Technical Challenges & Solutions
Despite their promise, diffusion language models face several significant technical challenges. Addressing these challenges is crucial for enabling these models to compete with or complement established autoregressive approaches.
The token discretization challenge in diffusion language models
Key Technical Challenges
Token Discretization Problem
Perhaps the most fundamental challenge is how to handle the discrete nature of language tokens in a continuous diffusion process. During generation, the model must eventually convert continuous vectors back into discrete tokens, which can lead to errors or inconsistencies if not handled carefully.
Adapting Classifier-Free Guidance
Classifier-free guidance has been a powerful technique for controlling image generation in diffusion models. Adapting this approach to language presents unique challenges, as the guidance must operate in a way that preserves grammatical structure and semantic coherence while still allowing for creativity.
Accelerated Sampling Algorithms
One advantage of traditional diffusion models is the availability of accelerated sampling techniques that reduce the number of steps needed for generation. Adapting these techniques to language diffusion models remains challenging due to the different statistical properties of language data.
Memory and Computation Considerations
Diffusion models typically require multiple forward passes during generation, which can lead to higher computational costs compared to autoregressive models. This is particularly challenging for long-form text generation, where the computational requirements can become prohibitive.
Innovative Solutions
Hybrid Model Architecture
Combining strengths of autoregressive and diffusion approaches
flowchart TB
subgraph "Hybrid Language Generation System"
AR[Autoregressive Component]
DF[Diffusion Component]
CP[Control Parameters]
Input[Text Prompt] --> CP
CP --> AR
CP --> DF
AR --> S1[Initial Structure\nGeneration]
DF --> S2[Holistic Refinement]
S1 --> Integration
S2 --> Integration
Integration --> Output[Final Text Output]
end
The diagram above illustrates a potential hybrid approach that combines the strengths of both autoregressive and diffusion models. In this architecture, an autoregressive component might generate an initial structural framework, while a diffusion component refines and enhances the output holistically. This hybrid approach could potentially overcome the limitations of each individual method.
Other promising solutions include:
- Categorical reparameterization tricks that allow for more efficient gradients through discrete sampling operations
- Progressive distillation techniques that reduce the number of sampling steps required during inference
- Modular architectures that separate the diffusion process into multiple specialized components
- Neural compression methods that reduce the dimensionality of the problem space
These technical challenges and emerging solutions represent the current frontier of diffusion language model research. As these challenges are addressed, we may see diffusion-based approaches become increasingly competitive with—and complementary to—traditional autoregressive language models for a growing range of applications. PageOn.ai's visualization tools can be particularly valuable for developers and researchers working to understand and overcome these complex technical challenges by providing clear, intuitive representations of model architectures and processes.
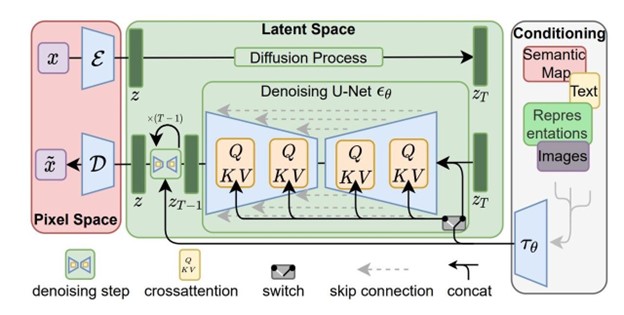
Visual-Linguistic Integration Through Diffusion
One of the most exciting aspects of diffusion models for language is their potential to create natural bridges between visual and linguistic domains. Unlike autoregressive models, which were designed specifically for sequential text generation, diffusion models share a common mathematical foundation across modalities, making them inherently more suited for multimodal tasks.

Shared latent space between visual and linguistic representations in diffusion models
Creating Semantically Coherent Multimodal Representations
Diffusion models excel at learning continuous representations that capture semantic relationships. When applied across modalities, these models can learn to align conceptual information between text and images, creating unified representations that preserve meaning across different forms of expression.
This alignment enables fascinating applications, such as:
- Text-guided image editing with precise semantic control
- Generating text descriptions that accurately capture visual nuances
- Translating concepts seamlessly between textual and visual forms
- Creating coherent multimodal content where text and images share contextual alignment
Multimodal Diffusion Process
Visualizing how concepts flow between text and image domains
graph LR
subgraph "Shared Latent Space"
LS((Latent\nRepresentations))
end
subgraph "Text Domain"
T1[Text Input] --> TE[Text Encoder]
TE --> LS
LS --> TD[Text Diffusion]
TD --> TG[Text Generator]
TG --> T2[Text Output]
end
subgraph "Image Domain"
I1[Image Input] --> IE[Image Encoder]
IE --> LS
LS --> ID[Image Diffusion]
ID --> IG[Image Generator]
IG --> I2[Image Output]
end
T1 -.Cross-Modal Generation.-> I2
I1 -.Cross-Modal Generation.-> T2
Using Stable Diffusion AI image creation as an example, we can observe how concepts expressed in language can be translated into visual representations through shared latent spaces. These models don't just learn to generate images from text prompts; they learn deep conceptual mappings between linguistic and visual domains.
Visualizing Complex Diffusion Processes with PageOn.ai
PageOn.ai's AI Blocks feature provides an ideal platform for visualizing complex language-to-image diffusion processes. These visualizations can help explain otherwise abstract concepts in intuitive ways:
Noise Scheduling Visualization
AI Blocks can represent the progressive addition and removal of noise across both text and image domains, showing how the diffusion process gradually transforms random noise into coherent content.
Latent Space Mapping
Creating interactive visualizations of the shared latent space between text and images, allowing users to explore how concepts are represented and related across modalities.
Attention Mechanism Flows
Visualizing how attention mechanisms in diffusion models connect specific words or phrases to visual elements, enhancing interpretability.
Cross-Modal Transfer
Creating diagrams that show how semantic information transfers between modalities, maintaining consistency of meaning and context.
PageOn.ai's Deep Search functionality further enhances this integration by enabling users to explore the outputs of multimodal diffusion models, finding connections and patterns that might otherwise remain hidden. This capability is particularly valuable for creative professionals working with AI speech generators and AI speech writing tools that may incorporate diffusion-based components.
As diffusion models continue to advance in both visual and linguistic domains, we can expect increasingly sophisticated integration between these modalities. The shared mathematical foundation of diffusion models provides a natural pathway for this integration, potentially leading to generative systems with deep cross-modal understanding and expression capabilities.
Practical Applications & Future Directions
As diffusion language models mature, they open up exciting possibilities for practical applications across numerous domains. While some of these applications overlap with those of traditional language models, diffusion-based approaches offer unique advantages for specific use cases.

Diverse applications of diffusion language models across industries
Emerging Use Cases
| Application Area | Unique Advantages of Diffusion | Example Use Case |
|---|---|---|
| Creative Writing | Holistic story structure; global narrative coherence | Plot development tools that ensure consistent character arcs and thematic elements |
| Technical Documentation | Maintaining consistent terminology and structure throughout long documents | Automated documentation systems that ensure API descriptions remain consistent |
| Multimodal Content Creation | Seamless integration between text and visual elements | Marketing materials with perfectly aligned messaging across text and images |
| Text Refinement | Iterative improvement while preserving overall structure | Advanced editing tools that enhance clarity while maintaining author voice |
| Knowledge Graphs | Representing complex relationships between concepts | Systems that build knowledge graph RAG systems with enhanced semantic understanding |
Industry Applications
Across industries, diffusion language models are finding specific applications that leverage their unique capabilities:
Publishing
Tools for editors and authors that suggest structural improvements and ensure narrative consistency across long-form content like novels or textbooks.
Marketing
Systems that generate consistent brand messaging across different content types and ensure harmony between textual and visual elements.
Education
Content creation tools that help educators develop coherent learning materials with consistent terminology and concepts, facilitating generating paper topics with integrated visual supports.
Research
Systems that assist in literature review by identifying conceptual connections across papers and suggesting areas for further investigation.
Visualizing Abstract Concepts with PageOn.ai
PageOn.ai provides particularly valuable tools for visualizing the abstract concepts involved in diffusion language models:
- Interactive visualizations of how noise is added and removed during the diffusion process
- Latent space explorations showing how language tokens relate to each other
- Process diagrams illustrating the step-by-step generation of text through diffusion
- Comparative visualizations of autoregressive vs. diffusion approaches
Research Frontiers
Active Research Areas in Diffusion Language Models
Key focus areas driving innovation in the field
The radar chart above highlights the areas of most intense research activity in diffusion language models. Multimodal integration currently leads as the most active area, reflecting the natural strengths of diffusion models in bridging different modalities. Computational efficiency remains a critical challenge that must be addressed for these models to achieve widespread adoption.
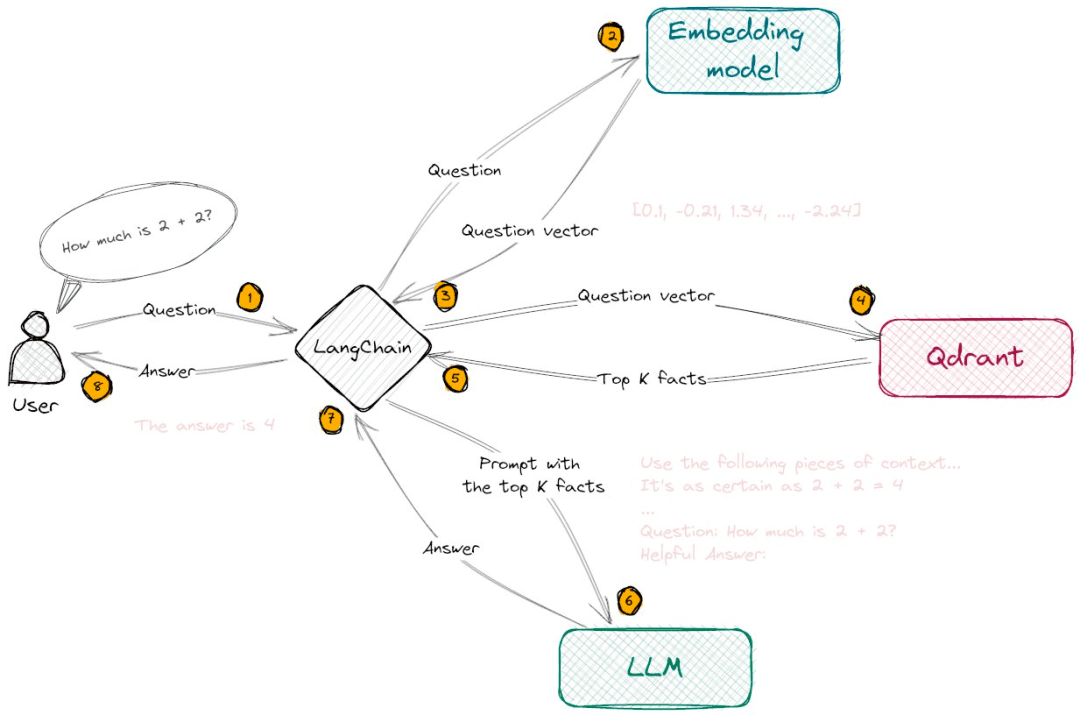
Implementing Diffusion Language Models in Real-World Systems
Moving from theoretical understanding to practical implementation of diffusion language models presents unique challenges. Organizations interested in deploying these models must consider several technical requirements and integration challenges.
System architecture for practical diffusion language model deployment
Technical Requirements
Computational Infrastructure
Diffusion language models typically require more computational resources during inference than autoregressive models, as they perform multiple forward passes to gradually denoise the output. Organizations need robust GPU infrastructure and optimized implementation to achieve reasonable response times.
Memory Management
These models can be memory-intensive, especially when generating longer text sequences. Efficient memory management strategies, including gradient checkpointing and mixed-precision training, are essential for practical deployment.
Optimization Techniques
Several optimization approaches can make diffusion language models more practical, including distillation to reduce inference steps, model quantization to decrease memory footprint, and specialized kernels for accelerated computation.
Integration with Existing LLM Infrastructure
Integration Architecture
How diffusion language models can integrate with existing LLM systems
flowchart TB
subgraph "Client Applications"
WebApp[Web Application]
Mobile[Mobile App]
API[API Consumers]
end
subgraph "Integration Layer"
Router[Request Router]
Cache[Response Cache]
Monitor[Performance Monitoring]
end
subgraph "Model Layer"
ARModel[Autoregressive Models]
DFModel[Diffusion Language Models]
Hybrid[Hybrid Models]
end
WebApp --> Router
Mobile --> Router
API --> Router
Router --> ARModel
Router --> DFModel
Router --> Hybrid
ARModel --> Cache
DFModel --> Cache
Hybrid --> Cache
Cache --> WebApp
Cache --> Mobile
Cache --> API
ARModel --> Monitor
DFModel --> Monitor
Hybrid --> Monitor
The diagram above illustrates how diffusion language models can be integrated into existing language model infrastructure. A well-designed integration layer can route requests to the appropriate model type based on the specific requirements of each task, allowing organizations to leverage the strengths of both diffusion and autoregressive approaches.
Key integration challenges include:
- API compatibility: Ensuring that diffusion models can be accessed through the same interfaces as existing language models
- Latency management: Developing strategies to handle the potentially longer inference times of diffusion models
- Fallback mechanisms: Creating robust systems that can fall back to faster models when response time is critical
- Monitoring and evaluation: Developing appropriate metrics to assess the performance of diffusion language models in production
Visualization Tools for Model Architecture
PageOn.ai's visualization tools are particularly valuable for teams implementing diffusion language models. These tools can help map complex model architectures, making them more accessible to both technical and non-technical stakeholders:
Architecture Diagrams
Visual representations of model components and their interactions, helping teams understand the flow of data through the system.
Process Flows
Step-by-step visualizations of how text is generated through the diffusion process, aiding in optimization and troubleshooting.
Performance Dashboards
Interactive visualizations of model performance metrics, helping teams identify bottlenecks and optimization opportunities.
Integration Maps
Visual representations of how diffusion language models connect with other system components, facilitating smoother integration.
Case Studies: Successful Implementations
While diffusion language models are still emerging, some organizations have already begun to implement them in specialized applications:
Research Lab: Long-Form Content Structure
A research organization implemented diffusion language models specifically for generating structured scientific abstracts, finding that the holistic generation approach led to more coherent summaries of complex research.
Creative Agency: Multimodal Content
A creative agency developed a system using diffusion models to simultaneously generate aligned textual and visual content for marketing campaigns, ensuring consistent messaging across modalities.
Educational Publisher: Content Refinement
An educational content provider implemented diffusion models as a refinement layer on top of autoregressive generation, using them to ensure consistent terminology and conceptual explanations across textbook chapters.
These case studies highlight how organizations are finding specific niches where diffusion language models offer advantages over traditional approaches. As the technology continues to mature, we can expect more diverse applications and integration strategies to emerge.
Transform Your Visual Expressions with PageOn.ai
Unlock the power of diffusion-based language modeling with PageOn.ai's advanced visualization tools. Create clear, intuitive representations of complex language modeling concepts and bridge the gap between different modalities.
Start Creating with PageOn.ai TodayConclusion: The Future of Diffusion in Language Modeling
The evolution of diffusion models from visual to linguistic domains represents one of the most exciting frontiers in generative AI. While autoregressive models have dominated language generation for years, diffusion-based approaches are beginning to challenge this paradigm by offering unique advantages for specific use cases.
As research continues to address the technical challenges of applying diffusion to discrete language tokens, we're likely to see increasingly sophisticated implementations that combine the best aspects of both approaches. The natural alignment between diffusion models across modalities also suggests a future where text and visual content generation become more integrated, enabling more coherent multimodal expressions.
For organizations and researchers exploring this frontier, tools like PageOn.ai provide essential capabilities for visualizing and communicating complex concepts. By making abstract mathematical processes more intuitive and accessible, these visualization tools can accelerate understanding and adoption of diffusion language models.
Whether diffusion models eventually supplant autoregressive approaches for language generation or the two paradigms evolve to complement each other, it's clear that the landscape of language modeling is expanding in exciting new directions. The bridges being built between visual and linguistic domains through diffusion techniques promise to unlock new creative possibilities and more natural human-machine interactions in the years ahead.
You Might Also Like
How to Design Science Lesson Plans That Captivate Students
Create science lesson plans that captivate students with hands-on activities, clear objectives, and real-world applications to foster curiosity and critical thinking.
How to Write a Scientific Review Article Step by Step
Learn how to write a review article in science step by step. Define research questions, synthesize findings, and structure your article for clarity and impact.
How to Write a Self-Performance Review with Practical Examples
Learn how to write a self-performance review with examples and tips. Use an employee performance review work self evaluation sample essay to guide your process.
How to Write a Spec Sheet Like a Pro? [+Templates]
Learn how to create a professional spec sheet with key components, step-by-step guidance, and free templates to ensure clarity and accuracy.