Understanding Text Diffusion Models: Transforming Random Noise into Coherent Content
Exploring the revolutionary technology behind converting noise into meaningful text
Text diffusion models represent a paradigm shift in how AI generates content, using a process of gradual denoising to create diverse and high-quality outputs. Discover how these probabilistic generative models work and why they're changing the landscape of AI text generation.
Foundations of Text Diffusion Technology
Text diffusion models function as probabilistic generative models that learn to create coherent content by gradually transforming random noise into meaningful text. Unlike deterministic approaches, these models work with probability distributions to generate a wide variety of outputs from the same input parameters.
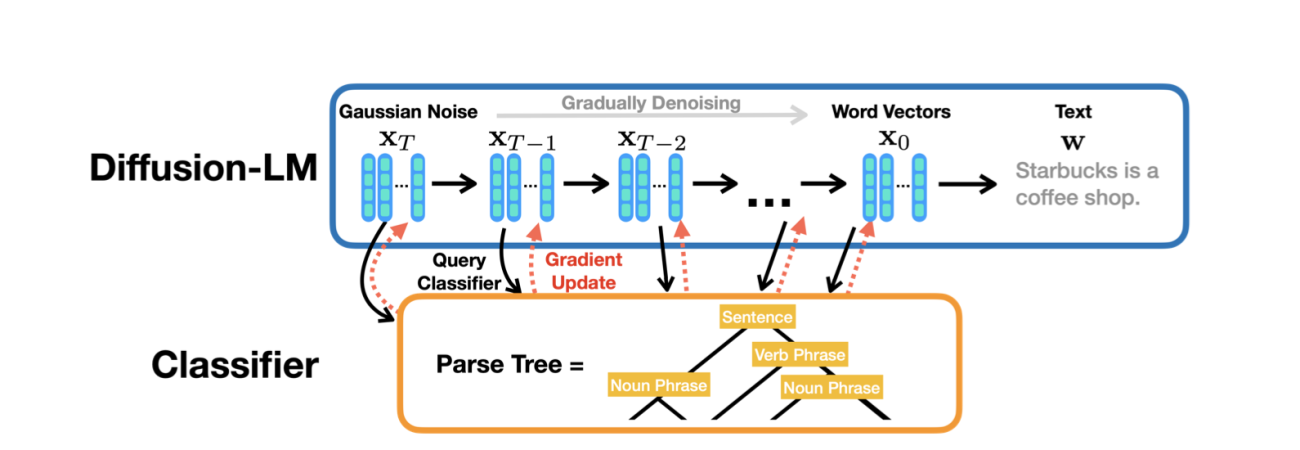
Comparison with Traditional Language Models
While traditional language models like GPT rely on predicting the next token in a sequence, text diffusion models approach generation differently. They excel in creating diverse outputs, offering significant advantages in generating text with varied styles, emotions, and themes. This makes them particularly valuable for creative applications where uniqueness is paramount.
Historical Evolution
Text diffusion models evolved from their image-based counterparts, which revolutionized Stable Diffusion AI image creation. Initial diffusion models were developed for continuous data like images, requiring significant adaptation to work with the discrete nature of text. This evolution has led to breakthrough models like Google's Gemini Diffusion, which applies the diffusion framework specifically to text generation challenges.
Key Mathematical Principles
At its core, text diffusion operates on the principle of gradually adding noise to data and then learning to reverse this process. The mathematical framework involves Markov chains and stochastic differential equations that model the transformation between noisy and clean states.
The Text Diffusion Process
The forward and reverse processes in text diffusion:
flowchart LR
A[Clean Text] -->|Forward Process\nAdd Noise Gradually| B[Noisy Text]
B -->|Reverse Process\nRemove Noise Gradually| C[Generated Text]
style A fill:#f0f8ff,stroke:#FF8000
style B fill:#ffebcc,stroke:#FF8000
style C fill:#f0f8ff,stroke:#FF8000
Gemini Diffusion: Pioneering Text Diffusion
Google's Gemini Diffusion represents a significant advancement in text diffusion technology. As highlighted by Google DeepMind, this state-of-the-art model learns to generate outputs by converting random noise into coherent text or code, similar to how current image and video generation models work. This approach has shown remarkable results in producing high-quality, diverse text across multiple domains.
The Technical Architecture Behind Text Diffusion
Text diffusion models employ a sophisticated architecture that enables the transformation of random noise into coherent text through a systematic process of noise addition and removal. Understanding this technical framework is essential for grasping how these models generate such diverse and high-quality outputs.
Forward and Reverse Diffusion Processes
Forward Diffusion Process
In the forward process, the model systematically adds noise to clean text data, gradually transforming it into a completely random distribution:
- Starting with clean text, small amounts of noise are added in multiple steps
- Each step moves the text further from its original meaning
- The process continues until the text becomes indistinguishable from random noise
Reverse Diffusion Process
The reverse process is where text generation occurs:
- Starting with random noise, the model learns to predict and remove noise
- Successive denoising steps gradually reveal coherent text
- The model must learn the probability distribution of the training data

Noise Introduction and Removal
The systematic addition and removal of noise follows specific mathematical formulations:
# Forward process (adding noise)
q(x_t | x_{t-1}) = N(x_t; sqrt(1-β_t)x_{t-1}, β_t𝐈)
# Reverse process (removing noise)
p_θ(x_{t-1} | x_t) = N(x_{t-1}; μ_θ(x_t, t), Σ_θ(x_t, t))
Where β_t represents the noise schedule, and the model learns the parameters μ_θ and Σ_θ to reverse the diffusion process effectively. The ability to generate AI social media post generators with unique styles can be attributed to this mathematically-grounded approach to controlled text generation.
Embedding Spaces for Text Representation
Text diffusion models require a continuous representation of discrete text data:
- Words or tokens are mapped to vector embeddings in a high-dimensional space
- These embeddings allow the diffusion process to operate on continuous data
- During generation, continuous vectors must be mapped back to discrete tokens
Implementation Challenges for Discrete Text Data
Text data presents unique challenges for diffusion models:
Key Challenges in Text Diffusion Implementation
Training Requirements and Computational Considerations
Text diffusion models are computationally intensive, requiring:
- Large datasets of high-quality text for training
- Significant GPU resources for both training and inference
- Careful tuning of the noise schedule and model hyperparameters
- Extended training periods compared to some traditional language models
Despite these challenges, text diffusion models have shown remarkable capabilities in generating diverse and high-quality text, making them valuable tools for content creation and natural language processing tasks.
Applications and Use Cases
Text diffusion models have opened new possibilities across multiple domains, offering unique capabilities for content generation and creative applications. Their ability to produce diverse outputs makes them particularly valuable for tasks requiring originality and stylistic variation.

Content Generation Capabilities
Text diffusion models excel at generating diverse content across various formats:
Content Generation Capabilities by Format
Zero-shot Problem Solving Advantages
One of the remarkable capabilities of text diffusion models is their zero-shot performance—the ability to tackle problems they weren't explicitly trained on:
- They leverage learned data distribution characteristics to generate reasonable outputs for unfamiliar tasks
- This enables adaptation to new domains without specific training examples
- For example, a model trained on general text can often generating paper topics in specialized fields
Creative Writing and Storytelling
Text diffusion models shine particularly bright in creative applications:
- Generating stories with unique narrative voices and stylistic variations
- Creating poetry that experiments with form and language
- Developing character dialogue that reflects distinct personalities
- Adapting writing to different genres and tones
Code Generation
Specialized text diffusion approaches have shown promising results in code generation:
- Creating syntactically valid code snippets across programming languages
- Generating alternative implementations of algorithms
- Proposing optimizations and refactoring suggestions
- Creating code that follows specified patterns or styles
PageOn.ai Integration Opportunity
PageOn.ai could revolutionize how we work with text diffusion models by integrating them into the content creation workflow. By combining text diffusion's creative diversity with structured visualization tools, PageOn.ai could transform unstructured ideas into coherent, visually engaging content that maintains the original creative intent while ensuring structural clarity. This integration would be particularly valuable for AI discussion post generators where both creativity and clarity are essential.
As these models continue to evolve, we can expect even more sophisticated applications across industries, particularly in content creation, marketing, and software development where diversity of outputs provides significant value.
Comparing Text Diffusion with Pre-trained Language Models
Text diffusion models and pre-trained language models (PLMs) represent different approaches to text generation, each with distinct strengths and limitations. Understanding these differences is crucial for selecting the right technology for specific applications.
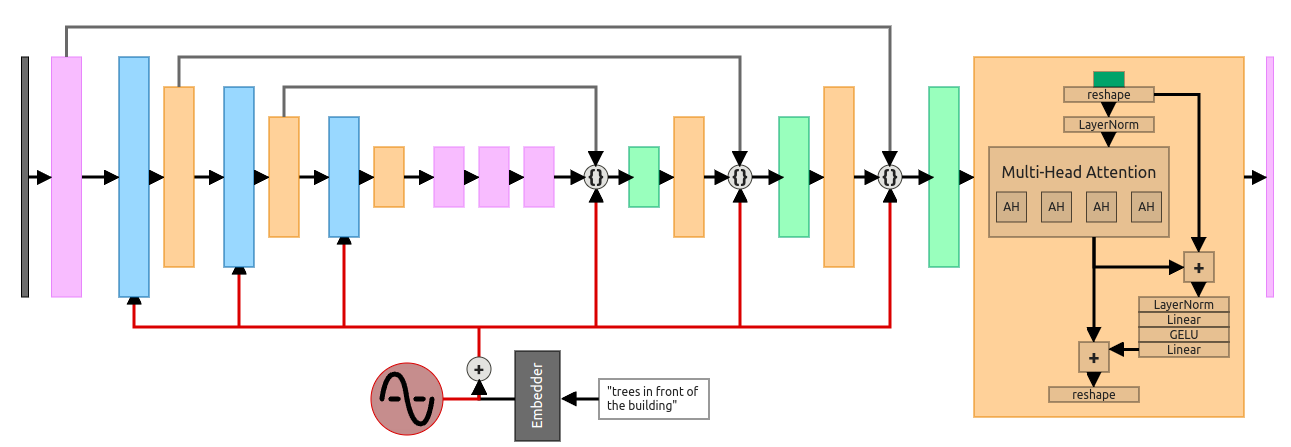
Comparative Analysis
| Aspect | Text Diffusion Models | Pre-trained Language Models |
|---|---|---|
| Generation Approach | Gradual denoising of random text | Sequential token prediction |
| Output Diversity | High - excellent for creative variations | Moderate - may converge on common patterns |
| Factual Accuracy | Lower - more prone to fabrication | Higher - better adherence to training facts |
| Logical Coherence | Moderate - may include inconsistencies | Higher - better at maintaining reasoning |
| Controllability | Moderate - control via conditioning | High - direct prompt engineering |
| Inference Speed | Slower - requires multiple denoising steps | Faster - single-pass token generation |
| Training Efficiency | More resource-intensive | Relatively more efficient |
When Text Diffusion Outperforms Traditional Models
Text diffusion models particularly excel in scenarios requiring:
- High stylistic diversity in outputs
- Creative content generation with unique perspectives
- Applications where output variety is more important than factual precision
- Situations benefiting from probabilistic modeling of language
Processing Efficiency Considerations
Model Performance Comparison
Potential Logical Inconsistencies
Text diffusion models may be more prone to certain types of errors:
- Internal contradictions within generated content
- Factual inaccuracies or fabricated information
- Occasional semantic drift during generation
- Less structured logical flow in complex reasoning tasks
PageOn.ai's Agentic Approach
PageOn.ai has the opportunity to combine the strengths of both model types through its agentic approach. By using text diffusion models for creative divergent thinking and pre-trained language models for structured, factual content, PageOn.ai can deliver both innovation and accuracy. This hybrid approach would be particularly valuable for AI create charts from text capabilities, where creativity in visualization must be balanced with factual accuracy in data representation.
The choice between text diffusion models and pre-trained language models ultimately depends on the specific requirements of your project. Understanding these tradeoffs is essential for selecting the appropriate technology for your text generation needs.
Practical Implementation Examples
Seeing text diffusion in action helps to understand its practical applications and capabilities. This section explores concrete implementations and visualizes the fascinating process of transforming random noise into coherent text.
Minimal Text Diffusion Implementation
A basic implementation of text diffusion involves several key components:
Core Components of a Text Diffusion Implementation
-
Text Tokenization and Embedding:
Convert discrete text into continuous vector representations that can undergo diffusion.
-
Noise Schedule Definition:
Determine how noise is gradually added during the forward process, often using a beta schedule.
-
Neural Network Architecture:
Design a model (typically U-Net or Transformer-based) that can predict and remove noise.
-
Training Loop:
Teach the model to predict the noise added to text at different noise levels.
-
Sampling Procedure:
Generate new text by starting with random noise and incrementally denoising.
Visualizing the Denoising Process
One of the most fascinating aspects of text diffusion is observing the gradual emergence of coherent text from random characters:
Text Diffusion Denoising Steps
Visualization of how random text gradually transforms into coherent content:
flowchart TD
A["Random Noise\n'xkf19 plwe @!3nm zq7'"] --> B["Step 1 (75% Noise)\n'the qu!ck br8wn 2ox ju@p'"]
B --> C["Step 2 (50% Noise)\n'the quick br*wn fox jum-'"]
C --> D["Step 3 (25% Noise)\n'the quick brown fox jum?'"]
D --> E["Final Text\n'the quick brown fox jumps'"]
style A fill:#ffcccc,stroke:#FF8000
style B fill:#ffd9cc,stroke:#FF8000
style C fill:#ffe6cc,stroke:#FF8000
style D fill:#fff2cc,stroke:#FF8000
style E fill:#e6ffcc,stroke:#FF8000
This process involves multiple steps of denoising, each bringing the text closer to a coherent form. The number of steps can be adjusted to balance quality with generation speed.
Gemini Diffusion Capabilities
Google's Gemini Diffusion represents a state-of-the-art implementation of text diffusion technology. It demonstrates several advanced capabilities:
- High-fidelity generation of complex text across multiple domains
- Effective conditioning on various input types
- Ability to maintain coherence across long-form content
- Robust code generation capabilities
- Flexibility in controlling stylistic elements
Real-world Transformation Examples
Creative Writing Example
Noise (100%): "klfh ajsdft hrut bnmck zoplit weasr ghty"
Step 1 (75%): "the forest thrl dark myst acrxss gloum"
Step 2 (50%): "the forest thrummed dark myst across gloomy"
Final: "The forest thrummed with dark mysteries across gloomy twilight."
Code Generation Example
Noise (100%): "pwq$ ftyu(zx) { vbn mju ikas }"
Step 1 (75%): "def$ fact(nx) { ret cal fibo }"
Step 2 (50%): "def fact(n) { return calc_fibonacci }"
Final: "def factorial(n): return 1 if n <= 1 else n * factorial(n-1)"
PageOn.ai's AI Blocks Visualization
PageOn.ai's AI Blocks feature presents a unique opportunity to visualize the progressive transformation in text diffusion. By creating visual blocks representing each stage of the denoising process, PageOn.ai could make this complex process intuitive and accessible. Users could observe how coherent text emerges step by step, with AI Blocks highlighting key transformations and preserving the intermediate stages that are typically hidden in most implementations.
These practical examples demonstrate the fascinating journey from random noise to meaningful text, showcasing the power and potential of text diffusion models in various applications.
Future Directions and Integration Possibilities
Text diffusion models are still in their early stages, with vast potential for advancement and integration into various applications. This section explores emerging research trends and possibilities for future development.
Emerging Research in Multi-modal Applications
Researchers are increasingly exploring how text diffusion models can interact with other modalities:
- Text-to-image generation pipelines that maintain semantic consistency
- Joint text and audio generation for narration and speech synthesis
- Text-to-video systems that create coherent visual narratives
- Interactive systems that allow real-time guidance of the diffusion process
Research Interest in Text Diffusion Applications
Combining Text and Visual Diffusion
One of the most promising directions is the integration of text and visual diffusion models:
- Unified models that can generate both text and images in a coherent context
- Systems that can translate between text and visual representations
- Interactive tools that allow users to guide generation across modalities
- Applications that maintain semantic consistency between text and visuals
Integration with Structured Document Generation
Text diffusion could revolutionize how we create structured documents:
- Generating consistent content across different document sections
- Creating variations of standard documents while maintaining required structure
- Adapting content to different formats while preserving meaning
- Enhancing templates with contextually appropriate content
Ethical Considerations and Responsible Deployment
As text diffusion models become more powerful, ethical considerations become increasingly important:
- Mitigating bias in generated content
- Ensuring transparency about AI-generated text
- Preventing misuse for misinformation or harmful content
- Balancing creative capabilities with responsible constraints
- Developing robust evaluation metrics beyond simple fluency
PageOn.ai's Deep Search Integration
PageOn.ai's Deep Search capability could significantly enhance text diffusion outputs by automatically identifying and suggesting relevant visual assets that align with generated content. This integration would create a seamless workflow where users can generate text through diffusion, then immediately access contextually appropriate visual elements to complement it. The result would be more cohesive, engaging content that maintains conceptual integrity across both textual and visual components.
The future of text diffusion models is bright, with numerous possibilities for advancement and integration. As research continues to evolve, we can expect these models to become even more versatile and powerful tools for content creation and natural language processing.
From Theory to Practice: Getting Started with Text Diffusion
For developers and researchers interested in exploring text diffusion models, this section provides practical guidance on implementation, configuration, and optimization.
Resources for Implementation
Several resources are available for those looking to implement text diffusion models:
Open Source Repositories
- Minimal text diffusion implementations
- Hugging Face diffusion models
- Research code from academic papers
Documentation & Tutorials
- Step-by-step implementation guides
- Mathematics explainers and tutorials
- Practical training workflows
Pre-trained Models
- Domain-specific diffusion models
- Fine-tunable base models
- Evaluation benchmarks and datasets
Key Parameters and Configurations
Several parameters significantly impact the performance of text diffusion models:
| Parameter | Description | Typical Values | Impact |
|---|---|---|---|
| Noise Schedule | Defines how noise is added during diffusion | Linear, Cosine, Quadratic | Affects stability and quality |
| Diffusion Steps | Number of denoising steps during generation | 20-1000 | Quality vs. speed tradeoff |
| Network Architecture | Model used to predict noise | Transformer, U-Net | Capability and resource usage |
| Guidance Scale | Controls influence of conditioning | 1.0-10.0 | Adherence to prompts |
| Sampling Method | Algorithm for probabilistic sampling | DDPM, DDIM, DPM-Solver | Generation quality and speed |
Performance Evaluation Metrics
Evaluating text diffusion outputs involves multiple dimensions:
Text Diffusion Evaluation Dimensions
Common Challenges and Troubleshooting
Implementers of text diffusion models often face several challenges:
- Mode Collapse: When the model produces limited variety despite different inputs
- Training Instability: Difficulties in maintaining stable training dynamics
- Coherence Issues: Problems with maintaining semantic consistency in longer outputs
- Computational Efficiency: Balancing generation quality with resource constraints
- Evaluation Complexity: Challenges in measuring diverse quality aspects
PageOn.ai's Visualization Advantage
PageOn.ai offers a unique approach to demystifying text diffusion through accessible visual explanations. By transforming complex technical concepts into clear, intuitive visuals, PageOn.ai makes it easier for developers and non-technical users alike to understand how text diffusion works. This visualization capability is particularly valuable for educational purposes, allowing users to see the progressive transformation of text during the diffusion process and understand the impact of different parameters on the final output.
With these resources and guidelines, developers can begin exploring the fascinating world of text diffusion models, experimenting with different configurations and applications to leverage their unique capabilities.
Transform Your Visual Expressions with PageOn.ai
Ready to turn complex text diffusion concepts into stunning visual representations? PageOn.ai makes it effortless to create clear, engaging visualizations that communicate technical ideas with impact.
Start Creating with PageOn.ai TodayEmbracing the Future of Text Generation
Text diffusion models represent a significant advancement in AI-powered content creation, offering unique capabilities in generating diverse, creative text. As these models continue to evolve, they promise to transform how we approach content creation across various domains.
Whether you're a developer looking to implement these models, a content creator seeking to leverage their creative potential, or simply interested in understanding this fascinating technology, the journey into text diffusion is just beginning. With tools like PageOn.ai to help visualize and communicate these complex concepts, the power of text diffusion becomes accessible to a wider audience.
The future of text generation lies in combining the creative diversity of diffusion models with the factual accuracy of traditional language models, creating systems that offer both innovation and reliability. As you explore this exciting field, remember that visualizing complex ideas clearly is key to understanding and applying them effectively—and that's exactly where PageOn.ai excels.
You Might Also Like
How to Design Science Lesson Plans That Captivate Students
Create science lesson plans that captivate students with hands-on activities, clear objectives, and real-world applications to foster curiosity and critical thinking.
How to Write a Scientific Review Article Step by Step
Learn how to write a review article in science step by step. Define research questions, synthesize findings, and structure your article for clarity and impact.
How to Write a Self-Performance Review with Practical Examples
Learn how to write a self-performance review with examples and tips. Use an employee performance review work self evaluation sample essay to guide your process.
How to Write a Spec Sheet Like a Pro? [+Templates]
Learn how to create a professional spec sheet with key components, step-by-step guidance, and free templates to ensure clarity and accuracy.