Building Effective RAG Systems
Visualizing the Integration of Custom Data with Language Models
I've spent years working with language models, and I've found that one of the most powerful techniques for enhancing their capabilities is Retrieval-Augmented Generation (RAG). In this guide, I'll walk you through how to effectively implement RAG systems that seamlessly integrate custom data with language models, illustrated with clear visual representations.
Understanding RAG Architecture Fundamentals
When I first encountered Retrieval-Augmented Generation (RAG), I immediately recognized its potential to revolutionize how we work with language models. At its core, RAG represents a paradigm shift in natural language processing by enabling AI systems to access and leverage information beyond their training data.
flowchart TD
User([User Query]) --> LLM[Language Model]
LLM --> QueryAnalysis[Query Analysis]
QueryAnalysis --> Retriever[Retrieval System]
Retriever <--> KB[(Knowledge Base)]
Retriever --> Context[Retrieved Context]
Context --> Augmentation[Context Augmentation]
User --> Augmentation
Augmentation --> EnhancedLLM[Enhanced Language Model]
EnhancedLLM --> Response([Generated Response])
classDef orange fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
classDef blue fill:#42A5F5,stroke:#1976D2,stroke-width:2px,color:white;
classDef green fill:#66BB6A,stroke:#388E3C,stroke-width:2px,color:white;
class Retriever,KB,Context orange
class LLM,QueryAnalysis,EnhancedLLM blue
class Augmentation green
Figure 1: Core components of a RAG system architecture showing data flow from user query to enhanced response
As illustrated in the diagram above, a RAG system consists of three main components:
- Retrieval Mechanism: This component searches for and extracts relevant information from an external knowledge base in response to user queries.
- Knowledge Base: A collection of documents, data sources, or information repositories that contain the custom data you want to integrate with your language model.
- Language Model Integration: The process of combining the retrieved information with the language model's capabilities to generate accurate, contextually relevant responses.
The beauty of RAG lies in how it bridges the gap between static model knowledge and dynamic external information. Traditional language models are limited to the knowledge they acquired during training, which can quickly become outdated. With RAG, I can keep my AI systems current by connecting them to fresh, custom data sources without requiring constant retraining.
Using PageOn.ai's AI Blocks, I've found that even team members without deep technical expertise can conceptualize and contribute to RAG architecture designs. The drag-and-drop interface makes it easy to visualize how different components interact, significantly accelerating our implementation process.
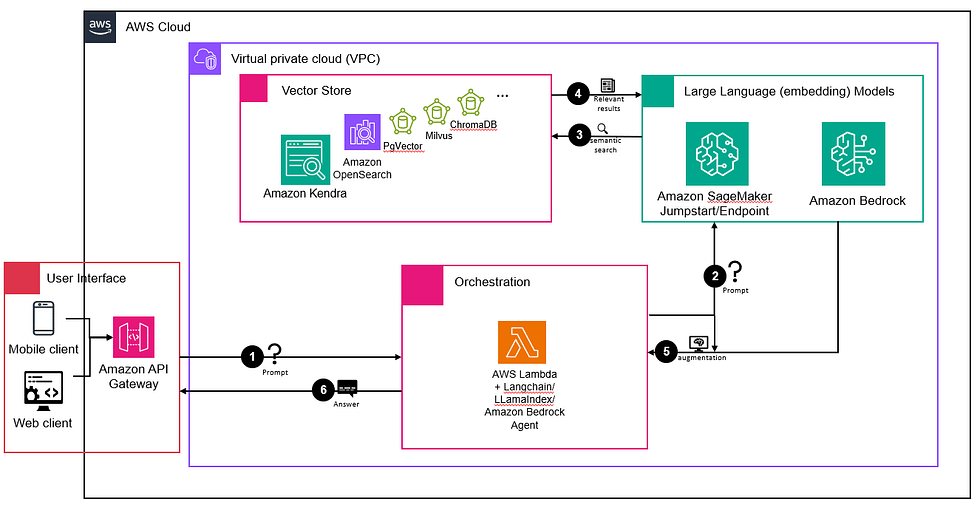
Creating an Effective Knowledge Base for RAG
In my experience, the quality of your knowledge base directly determines the effectiveness of your RAG system. Creating a well-structured, comprehensive knowledge base requires careful attention to document preparation, embedding generation, and metadata extraction.
Document Preparation and Preprocessing
Before documents can be effectively retrieved, they need to be properly prepared. I typically follow these preprocessing steps:
flowchart LR
Raw[Raw Documents] --> Extract[Text Extraction]
Extract --> Clean[Cleaning & Normalization]
Clean --> Chunk[Chunking]
Chunk --> Enrich[Metadata Enrichment]
Enrich --> Ready[Processed Documents]
classDef process fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
class Extract,Clean,Chunk,Enrich process
Figure 2: Document preprocessing workflow for RAG knowledge base preparation
- Text Extraction: Convert various file formats (PDF, DOCX, HTML) to plain text while preserving important structural information.
- Cleaning & Normalization: Remove irrelevant elements like headers/footers, standardize formatting, and fix encoding issues.
- Chunking: Divide documents into manageable segments that balance context preservation with retrieval granularity.
- Metadata Enrichment: Add tags, categories, and other metadata to enhance retrieval precision.
Embedding Generation
Embeddings are the backbone of efficient retrieval in RAG systems. These numerical representations capture the semantic meaning of text, allowing for similarity-based search.
When selecting an embedding model, I consider factors such as dimensionality, domain specificity, and computational requirements. In my projects, I've found that domain-specific fine-tuned models often outperform general-purpose ones, especially for specialized knowledge bases.
PageOn.ai's Deep Search functionality has been invaluable for our team when integrating diverse document types into our knowledge base. The visual interface makes it easy to monitor the embedding process and identify potential issues before they impact retrieval performance.
Knowledge Graph Approaches
While vector-based retrieval is powerful, I've found that incorporating knowledge graph RAG systems can significantly enhance retrieval by capturing structural relationships between entities. This hybrid approach provides context that pure vector similarity might miss.
By representing relationships explicitly, knowledge graphs enable more sophisticated query understanding and contextually aware retrieval. This is especially valuable for domains with complex interconnected concepts.
Designing the Retrieval Mechanism
The retrieval mechanism is the bridge between user queries and your knowledge base. Its effectiveness determines whether the most relevant information reaches your language model.
Similarity Search Algorithms
| Algorithm | Strengths | Limitations | Best Use Cases |
|---|---|---|---|
| Exact kNN | High precision | Slow with large datasets | Small to medium knowledge bases |
| Approximate kNN (HNSW) | Fast retrieval, scales well | Slight precision tradeoff | Large-scale production systems |
| Dense Retrieval | Semantic understanding | Misses exact keyword matches | Conceptual queries |
| Hybrid Search | Balances precision and recall | More complex implementation | General-purpose RAG systems |
In my implementations, I've found that hybrid retrieval approaches combining semantic and keyword-based search often deliver the best results. This allows the system to capture both the conceptual meaning of queries and specific terminology.
flowchart TD
Query([User Query]) --> Process[Query Processing]
Process --> Split{Retrieval Strategy}
Split -->|Semantic| Dense[Dense Retrieval]
Split -->|Lexical| Sparse[Sparse Retrieval]
Dense --> Embed[Query Embedding]
Embed --> Vector[(Vector DB)]
Vector --> SimResults[Similarity Results]
Sparse --> Tokenize[Tokenization]
Tokenize --> Inverted[(Inverted Index)]
Inverted --> KeywordResults[Keyword Results]
SimResults --> Rerank{Reranking}
KeywordResults --> Rerank
Rerank --> TopK[Top-K Results]
classDef orange fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
classDef blue fill:#42A5F5,stroke:#1976D2,stroke-width:2px,color:white;
class Dense,Embed,Vector,SimResults orange
class Sparse,Tokenize,Inverted,KeywordResults blue
Figure 3: Hybrid retrieval workflow combining semantic and keyword-based search
Ranking and Filtering Processes
Once potential context candidates are retrieved, they need to be ranked and filtered to select the most relevant information. This process involves:
- Relevance Scoring: Calculating how closely each retrieved document matches the query intent.
- Diversity Consideration: Ensuring varied perspectives when appropriate.
- Metadata Filtering: Using document attributes to narrow down results.
- Recency Weighting: Prioritizing more recent information when temporal relevance matters.
With PageOn.ai, I've been able to visualize complex retrieval workflows through intuitive block-based diagrams. This has been particularly helpful when explaining our system architecture to non-technical stakeholders and getting their input on retrieval priorities.
Integrating Retrieved Context with Language Models
The final piece of the RAG puzzle is effectively integrating retrieved context with language models. This step determines how well your system can leverage the retrieved information to generate accurate, helpful responses.
Prompt Engineering for Context Injection
I've found that the structure and framing of prompts significantly impact how well language models utilize retrieved context. Here are some effective prompt engineering techniques I use:
Basic Context Injection
context = "..." # Retrieved information
query = "..." # User question
prompt = f"""
Use the following information to answer the question.
INFORMATION:
{context}
QUESTION:
{query}
ANSWER:
"""
Advanced Context Injection
contexts = [...] # Multiple retrieved passages
query = "..." # User question
prompt = f"""
Use the following information sources to answer the question.
If the information is insufficient, say so.
Cite sources using [1], [2], etc.
SOURCES:
{format_sources(contexts)}
QUESTION:
{query}
ANSWER:
"""
flowchart TD
Query([User Query]) --> QueryEmbed[Query Embedding]
QueryEmbed --> Retrieval[Retrieve Relevant Context]
Retrieval --> Context[Retrieved Documents]
Context --> Processing[Context Processing]
Processing --> Truncation[Context Truncation]
Processing --> Ordering[Context Ordering]
Processing --> Highlighting[Key Info Highlighting]
Truncation & Ordering & Highlighting --> Assembly[Prompt Assembly]
Query --> Assembly
Assembly --> LLM[Language Model]
LLM --> Response([Generated Response])
classDef orange fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
classDef blue fill:#42A5F5,stroke:#1976D2,stroke-width:2px,color:white;
classDef green fill:#66BB6A,stroke:#388E3C,stroke-width:2px,color:white;
class Retrieval,Context orange
class Processing,Truncation,Ordering,Highlighting blue
class Assembly green
Figure 4: Context processing and integration workflow for RAG systems
Handling Context Limitations
Most language models have token limits that constrain how much context can be included. I use these strategies to address this challenge:
- Context Prioritization: Ranking retrieved passages by relevance and including only the most important ones.
- Summarization: Condensing lengthy contexts while preserving key information.
- Chunking: Breaking responses into multiple turns when extensive context is necessary.
- Information Extraction: Pulling only the most relevant facts from retrieved documents.
PageOn.ai's Vibe Creation has been instrumental in translating our technical integration concepts into clear visual workflows. This has helped our entire team understand how context moves through our system, from retrieval to final response generation.
The integration of API integration patterns for AI can further enhance how your RAG system processes and incorporates retrieved context, especially when working with multiple data sources or services.
Evaluating and Optimizing RAG System Performance
Measuring and optimizing RAG system performance is crucial for ensuring your implementation meets user needs. I've developed a comprehensive evaluation framework that examines multiple aspects of system behavior.
Fine-tuning Retrieval Precision and Recall
Balancing precision (retrieving only relevant documents) and recall (retrieving all relevant documents) is essential for RAG system effectiveness. I use these techniques to optimize retrieval:
- Query Expansion: Adding related terms to queries to improve recall.
- Threshold Tuning: Adjusting similarity thresholds based on performance data.
- Reranking: Using a secondary model to reorder initial retrieval results.
- Ensemble Methods: Combining multiple retrieval approaches for improved performance.
Debugging Common RAG Implementation Challenges
| Challenge | Symptoms | Debugging Approach |
|---|---|---|
| Hallucination | Generated responses contain incorrect information not in the retrieved context | Adjust prompt to emphasize source fidelity; increase retrieval precision |
| Retrieval Misalignment | System retrieves technically related but contextually irrelevant information | Improve embedding quality; implement query rewriting |
| Context Neglect | Model ignores retrieved information and relies on parametric knowledge | Restructure prompt to emphasize context; adjust temperature settings |
| Token Limitations | Context truncation leads to incomplete information | Implement better chunking strategies; use summarization |
PageOn.ai has transformed how we visualize and communicate complex performance metrics to our team. Instead of drowning in spreadsheets, we now use intuitive visualizations that highlight areas for improvement and track our progress over time.

Real-World RAG Implementation Case Studies
To illustrate how RAG systems work in practice, I'd like to share some implementation examples across different domains. These case studies highlight various approaches and considerations.
Enterprise Knowledge Management
flowchart TD
subgraph "Data Sources"
Docs[Internal Documents]
Wiki[Corporate Wiki]
Email[Email Archives]
end
subgraph "Processing Pipeline"
Extract[Extraction & Cleaning]
Embed[Embedding Generation]
Index[Vector Indexing]
end
subgraph "Retrieval System"
Query[Query Processing]
Search[Hybrid Search]
Rank[Relevance Ranking]
end
subgraph "Response Generation"
Context[Context Assembly]
LLM[Language Model]
Format[Response Formatting]
end
Docs & Wiki & Email --> Extract
Extract --> Embed
Embed --> Index
User([User Query]) --> Query
Query --> Search
Search <--> Index
Search --> Rank
Rank --> Context
User --> Context
Context --> LLM
LLM --> Format
Format --> Response([Generated Response])
classDef orange fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
classDef blue fill:#42A5F5,stroke:#1976D2,stroke-width:2px,color:white;
classDef green fill:#66BB6A,stroke:#388E3C,stroke-width:2px,color:white;
class Docs,Wiki,Email,Extract,Embed,Index orange
class Query,Search,Rank blue
class Context,LLM,Format green
Figure 5: Enterprise RAG implementation architecture showing integration of multiple data sources
In this enterprise implementation, the RAG system integrates multiple internal data sources to provide employees with accurate, up-to-date information. Key features include:
- Role-based Access Control: Ensuring users only retrieve information they're authorized to access.
- Freshness Weighting: Prioritizing more recent information when temporal relevance matters.
- Source Attribution: Clearly indicating which internal documents provided the information.
- Confidence Scoring: Providing users with a reliability indicator for generated responses.
Open-Source vs. Proprietary Solutions
When implementing RAG systems, one of the key decisions is whether to use open-source components or proprietary solutions. My experience with building RAG with open-source and custom AI models has shown that each approach has distinct advantages depending on your requirements.
PageOn.ai has been invaluable for our team's collaborative design and refinement of RAG systems. The shared visual workspace allows engineers, product managers, and subject matter experts to contribute their insights and identify potential improvements.

Future Directions and Advanced RAG Techniques
The field of RAG is evolving rapidly, with new techniques and approaches emerging regularly. Here are some exciting directions I'm exploring in my own work.
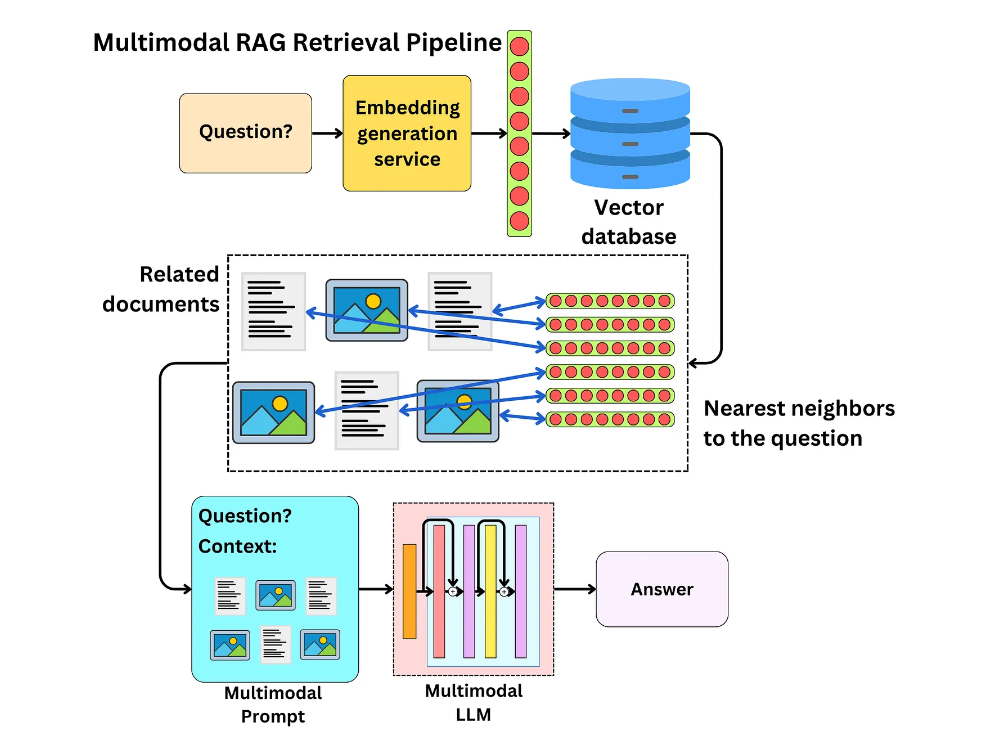
Multi-modal RAG Systems
Traditional RAG systems focus on text, but multi-modal RAG extends this concept to include images, audio, and video. This opens up fascinating possibilities for more comprehensive knowledge retrieval and generation.
flowchart TD
Input([Multi-modal Input]) --> Analysis[Input Analysis]
Analysis -->|Text| TextProc[Text Processing]
Analysis -->|Image| ImgProc[Image Processing]
Analysis -->|Audio| AudioProc[Audio Processing]
TextProc --> TextEmbed[Text Embeddings]
ImgProc --> ImgEmbed[Image Embeddings]
AudioProc --> AudioEmbed[Audio Embeddings]
TextEmbed & ImgEmbed & AudioEmbed --> Fusion[Embedding Fusion]
Fusion --> Retrieval[Multi-modal Retrieval]
Retrieval --> TextDocs[Retrieved Text]
Retrieval --> Images[Retrieved Images]
Retrieval --> Audio[Retrieved Audio]
TextDocs & Images & Audio --> Integration[Context Integration]
Integration --> LLM[Multi-modal LLM]
LLM --> Response([Generated Response])
classDef orange fill:#FF8000,stroke:#FF6000,stroke-width:2px,color:white;
classDef blue fill:#42A5F5,stroke:#1976D2,stroke-width:2px,color:white;
classDef green fill:#66BB6A,stroke:#388E3C,stroke-width:2px,color:white;
class TextProc,ImgProc,AudioProc,TextEmbed,ImgEmbed,AudioEmbed orange
class Fusion,Retrieval blue
class Integration,LLM green
Figure 6: Multi-modal RAG architecture supporting text, image, and audio inputs and retrieval
The integration of diffusion models language generation techniques with RAG systems represents another promising frontier, potentially allowing for more creative and nuanced content generation based on retrieved information.
Advanced RAG Integration Techniques
Beyond basic RAG implementations, several advanced techniques are showing promising results:
- Recursive Retrieval: Using initial generation to guide additional retrieval steps.
- Self-Reflection RAG: Allowing the model to critique its own retrieval and generation.
- Hypothetical Document RAG: Generating synthetic documents to fill knowledge gaps.
- Multi-Query RAG: Reformulating the original query in multiple ways to improve retrieval coverage.
PageOn.ai's agentic capabilities have been instrumental in helping our team stay ahead of evolving RAG methodologies. The platform's ability to visualize complex relationships and workflows makes it easier to experiment with and implement cutting-edge techniques.
The application of language functions lesson planning concepts can also enhance RAG systems, particularly in educational contexts where the system needs to adapt its responses based on pedagogical goals.
As RAG systems continue to evolve, tools like ai word search solver demonstrate how specialized retrieval techniques can be applied to niche domains, pointing toward a future of increasingly specialized and capable RAG implementations.
Transform Your RAG Implementations with PageOn.ai
Ready to take your RAG systems to the next level? PageOn.ai provides the visual tools you need to design, implement, and optimize custom data integration with language models. Turn complex technical concepts into clear, actionable visualizations.
Start Creating with PageOn.ai TodayConclusion: The Future of RAG Systems
Throughout this guide, I've shared my experience implementing RAG systems that effectively integrate custom data with language models. From building robust knowledge bases to designing efficient retrieval mechanisms and optimizing performance, we've covered the essential components of successful RAG implementations.
As we look to the future, RAG systems will continue to evolve, incorporating multi-modal capabilities, more sophisticated retrieval techniques, and tighter integration with other AI enhancement approaches. These advancements will enable even more powerful applications across industries.
Remember that visualizing these complex systems is key to understanding, implementing, and optimizing them effectively. Tools like PageOn.ai make this visualization process accessible and intuitive, helping teams collaborate more effectively and communicate complex technical concepts clearly.
I encourage you to explore the techniques and approaches we've discussed, adapt them to your specific use cases, and continue pushing the boundaries of what's possible with RAG systems. The integration of custom data with language models represents one of the most promising frontiers in AI today.
You Might Also Like
The AI Superpower Timeline: Visualizing US-China AI Race & Tech Developments
Explore the narrowing US-China AI performance gap, historical milestones, technical battlegrounds, and future projections in the global artificial intelligence race through interactive visualizations.
Building Trust in AI-Generated Marketing Content: Transparency, Security & Credibility Strategies
Discover proven strategies for establishing authentic trust in AI-generated marketing content through transparency, behavioral intelligence, and secure data practices.
Transform Your AI Results by Mastering the Art of Thinking in Prompts | Strategic AI Communication
Master the strategic mindset that transforms AI interactions from fuzzy requests to crystal-clear outputs. Learn professional prompt engineering techniques that save 20+ hours weekly.
How AI Amplifies Marketing Team Capabilities While Preserving Human Jobs | Strategic Marketing Enhancement
Discover how AI transforms marketing teams into powerhouses without reducing workforce size. Learn proven strategies for capability multiplication and strategic enhancement.