The Ultimate Guide to Evaluating and Selecting LLMs
Turning Complex Model Assessment into Clear Visual Frameworks
In today's rapidly evolving AI landscape, selecting the right Large Language Model (LLM) for your project can be the difference between transformative success and costly failure. I've created this comprehensive guide to help you navigate the complex process of evaluating and selecting LLMs through clear visual frameworks and systematic approaches.

Understanding the LLM Evaluation Landscape
LLM evaluation is the systematic process of assessing how well a Large Language Model performs against defined criteria and expectations. Unlike traditional software testing that checks deterministic code, I've found that LLM evaluation requires a fundamentally different approach to account for models' non-deterministic and context-dependent behavior.
When I evaluate LLMs, I distinguish between general capabilities (like reasoning, knowledge recall, and creative generation) and task-specific performance metrics (such as accuracy in classification or quality in translation). This distinction is crucial for developing a comprehensive evaluation strategy.
flowchart TD
A[LLM Evaluation Landscape] --> B[General Capabilities]
A --> C[Task-Specific Performance]
A --> D[Operational Considerations]
A --> E[Ethical Dimensions]
B --> B1[Reasoning]
B --> B2[Knowledge Recall]
B --> B3[Creative Generation]
B --> B4[Instruction Following]
C --> C1[Classification Accuracy]
C --> C2[Translation Quality]
C --> C3[Summarization Effectiveness]
C --> C4[Question Answering Precision]
D --> D1[Latency]
D --> D2[Throughput]
D --> D3[Resource Utilization]
D --> D4[Scalability]
E --> E1[Bias Detection]
E --> E2[Toxicity Filtering]
E --> E3[Privacy Preservation]
E --> E4[Safety Guardrails]
style A fill:#FF8000,stroke:#333,stroke-width:2px
style B fill:#42A5F5,stroke:#333,stroke-width:1px
style C fill:#66BB6A,stroke:#333,stroke-width:1px
style D fill:#FFA726,stroke:#333,stroke-width:1px
style E fill:#EF5350,stroke:#333,stroke-width:1px
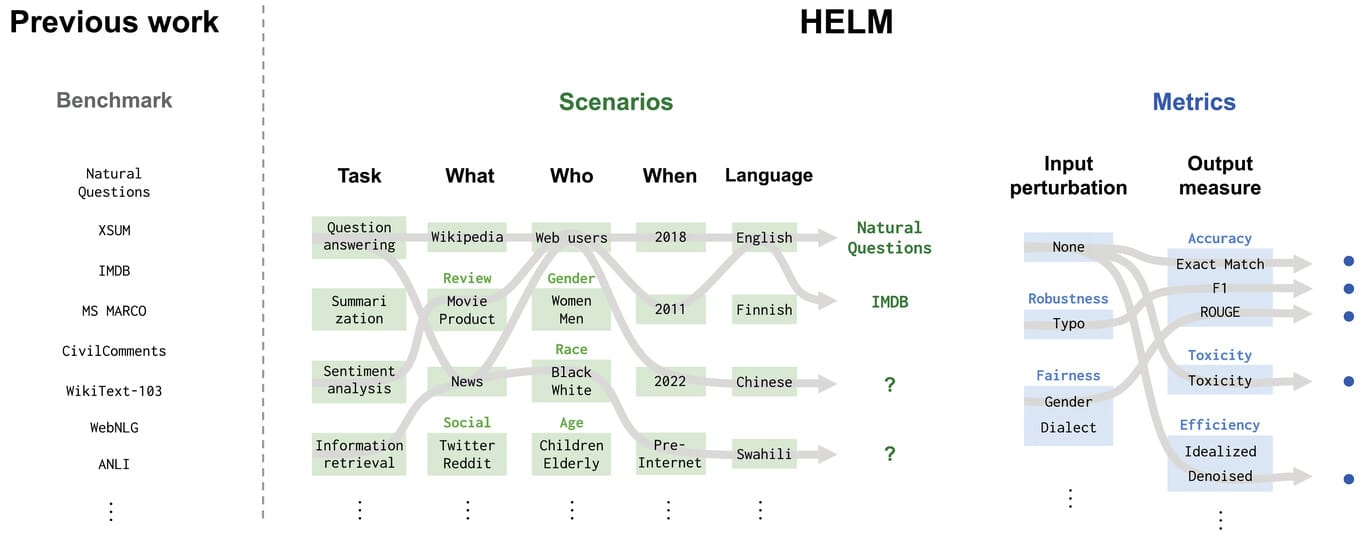
The evaluation spectrum ranges from technical benchmarks (like MMLU, HellaSwag, or BIG-bench) to real-world application testing with actual users and use cases. A comprehensive approach incorporates both ends of this spectrum to ensure models perform well not just in controlled environments but also in production scenarios.
I've found that visualizing evaluation frameworks helps tremendously in clarifying the assessment approach. For instance, using PageOn.ai's visualization tools, I can create comprehensive evaluation framework diagrams that make complex assessment strategies accessible to both technical and non-technical stakeholders.
Establishing Your Evaluation Criteria Framework
When I develop an evaluation framework for LLM selection, I start by identifying the core performance dimensions that matter most to the specific project. These typically include accuracy (correctness of outputs), relevance (appropriateness to the query), consistency (stability of responses across similar inputs), and reliability (dependability under various conditions).
The key to effective evaluation is mapping your business requirements directly to specific metrics. For instance, if your application needs to generate precise technical content, factual accuracy would receive higher weighting than creative expression.
Weighted Evaluation Criteria by Use Case
The chart below shows how evaluation criteria weightings might shift based on different LLM application types:
I've found that creating visual decision matrices is invaluable for stakeholder alignment. These matrices help everyone understand how different criteria are weighted and how they contribute to the final selection decision. Using language diffusion models can also help in refining these evaluation frameworks through progressive improvement.
For my projects, I leverage PageOn.ai's AI Blocks to build customizable evaluation scorecards. These visual tools allow me to create evaluation frameworks that evolve with my project needs, ensuring that the assessment criteria remain relevant as both the project and LLM capabilities mature.

Technical Evaluation Methodologies
Technical evaluation of LLMs involves implementing benchmark testing across standard NLP tasks. I typically assess models on tasks like question answering, text classification, summarization, and translation using established benchmarks such as GLUE, SuperGLUE, MMLU, and domain-specific datasets relevant to my use case.
Beyond accuracy, I measure computational efficiency through metrics like latency (response time), throughput (requests handled per unit time), and resource utilization (memory and compute requirements). These operational considerations are critical for production deployments where performance constraints may exist.
LLM Performance Comparison
Comparing popular LLMs across key technical metrics:
Context window limitations are another critical factor I evaluate. The maximum context length directly impacts how much information an LLM can process at once, affecting applications that require analysis of lengthy documents or maintaining extended conversations. I assess not just the theoretical maximum but the practical quality of responses across varying context lengths.
Fine-tuning potential is increasingly important in my evaluations. I assess how well models can adapt to specific domains or tasks through fine-tuning or other adaptation techniques. This includes evaluating the data efficiency (how much training data is needed) and the resulting performance improvements.
Offline Testing Strategies
For comprehensive evaluation, I build test suites with diverse edge cases that challenge the model across different dimensions. This includes testing for robustness against adversarial inputs, handling of ambiguous queries, and performance on domain-specific terminology.
flowchart TD
A[Offline Testing Pipeline] --> B[Test Suite Generation]
A --> C[Automated Evaluation]
A --> D[Result Analysis]
A --> E[Improvement Feedback Loop]
B --> B1[Standard Benchmarks]
B --> B2[Domain-Specific Cases]
B --> B3[Edge Cases]
B --> B4[Adversarial Examples]
C --> C1[Accuracy Metrics]
C --> C2[Latency Measurement]
C --> C3[Resource Utilization]
C --> C4[Safety Compliance]
D --> D1[Performance Visualization]
D --> D2[Error Analysis]
D --> D3[Pattern Recognition]
D --> D4[Comparative Ranking]
E --> E1[Model Selection Decisions]
E --> E2[Fine-tuning Recommendations]
E --> E3[Prompt Engineering Adjustments]
E --> B
style A fill:#FF8000,stroke:#333,stroke-width:2px
I implement automated evaluation pipelines for continuous assessment, using tools like diffusion models language generation techniques to create varied test inputs. These pipelines help monitor performance over time and across different versions of the model.
Tools like OpenAI's Eval framework and Weights & Biases (W&B) Weave have been invaluable in my systematic testing efforts. They provide structured ways to organize evaluations and track results across multiple dimensions.
For complex test results, I use PageOn.ai to transform data into clear comparative visualizations. These visual representations help stakeholders understand performance variations across different test scenarios and make informed decisions about which model best suits their needs.
Ethical and Safety Considerations
In my experience, ethical evaluation of LLMs is not optional but essential. I systematically assess models for bias, fairness, and toxicity across diverse content domains. This includes testing how models respond to queries about sensitive topics and checking for disparities in performance across different demographic groups.
Red-teaming exercises have become a crucial part of my evaluation process. These involve deliberately attempting to elicit harmful, biased, or otherwise problematic outputs from the model to identify vulnerabilities before deployment. I document these findings carefully to inform the development of appropriate guardrails.
Safety Evaluation Framework
Comprehensive assessment across key safety dimensions:
| Safety Dimension | Testing Method | Mitigation Strategy |
|---|---|---|
| Harmful Content Generation | Red-teaming with adversarial prompts | Content filtering, response refusal mechanisms |
| Bias and Fairness | Demographic representation testing, sentiment analysis across groups | Bias detection algorithms, balanced training data |
| Misinformation | Fact-checking against trusted sources, contradiction detection | Source attribution, confidence scoring, uncertainty indicators |
| Privacy Violations | PII extraction attempts, data leakage testing | Data anonymization, PII detection and redaction |
| Malicious Use | Security vulnerability probing, code injection testing | Intent classification, usage monitoring, access controls |
Alignment with organizational values and responsible AI principles is another dimension I evaluate. This involves checking whether the model's outputs consistently reflect the ethical standards and principles the organization has committed to upholding.
Based on evaluation findings, I create specific guardrails for deployment. These might include content filtering systems, topic restrictions, or monitoring mechanisms that flag potentially problematic outputs for human review.
For complex safety frameworks, I use PageOn.ai's Vibe Creation to develop scenario-based safety testing narratives. This approach helps visualize potential risks and mitigation strategies in a way that's accessible to both technical and ethical oversight teams.

Practical Selection Process
In my experience, a staged evaluation funnel is the most effective approach for LLM selection. This starts with initial screening based on basic requirements (like pricing, availability, and general capabilities), followed by progressively deeper assessments of shortlisted models.
flowchart TD
A[LLM Selection Process] --> B[Initial Screening]
B --> C[Technical Evaluation]
C --> D[Ethical Assessment]
D --> E[Pilot Testing]
E --> F[Final Selection]
B --> B1[Cost Structure]
B --> B2[API Availability]
B --> B3[Basic Capabilities]
B --> B4[Vendor Reputation]
C --> C1[Benchmark Performance]
C --> C2[Computational Requirements]
C --> C3[Fine-tuning Potential]
C --> C4[Integration Complexity]
D --> D1[Bias Evaluation]
D --> D2[Safety Testing]
D --> D3[Alignment Assessment]
D --> D4[Risk Analysis]
E --> E1[Small-scale Deployment]
E --> E2[User Feedback]
E --> E3[Performance Monitoring]
E --> E4[Refinement Cycle]
F --> F1[Final Model Selection]
F --> F2[Implementation Planning]
F --> F3[Monitoring Framework]
F --> F4[Continuous Improvement]
style A fill:#FF8000,stroke:#333,stroke-width:2px
style F fill:#66BB6A,stroke:#333,stroke-width:2px
I create decision trees for model selection based on application requirements. These structured frameworks help navigate the complex decision space by clarifying which factors are most important for specific use cases and how different requirements might lead to different optimal choices.
Cost-benefit analysis is crucial in my selection process. I build frameworks that account for various deployment scenarios, considering not just the direct costs (API calls, compute resources) but also indirect costs like implementation effort, maintenance, and potential risks.
Even after deployment, I establish ongoing evaluation protocols. LLMs and their applications evolve over time, so continuous monitoring and reassessment are essential to ensure the selected model continues to meet requirements.
For complex selection workflows, I leverage PageOn.ai's agentic capabilities to transform evaluation criteria into actionable processes. This helps ensure that all stakeholders understand not just what model was selected, but why it was the optimal choice for the specific use case. Using free ai document translators can also help make these selection frameworks accessible to global teams.
LLM Selection Cost-Benefit Analysis
Comparing total cost of ownership across deployment options:
Real-World Application Testing
Beyond technical evaluations, I've found that user acceptance testing is critical for LLM-powered applications. This involves designing protocols that assess how well the model meets user expectations and requirements in realistic scenarios, often involving actual end-users in the evaluation process.
I implement A/B testing frameworks to compare model performance in live environments. By routing a percentage of traffic to different models or configurations, I can gather empirical data on which performs better for real users with real tasks.
User Satisfaction Comparison
Results from A/B testing of different LLM implementations:
Creating effective feedback loops is essential for continuous improvement. I design mechanisms to collect, analyze, and act on user feedback about model outputs, using this information to refine prompts, fine-tune models, or adjust filtering mechanisms.
Beyond technical metrics, I measure business impact metrics like user satisfaction, task completion rates, time saved, or revenue generated. These metrics help connect LLM performance to actual business outcomes, making the value proposition clear to stakeholders.
For visualizing user journeys with LLM touchpoints, I use PageOn.ai to create clear maps that show where and how the model interacts with users. These visualizations include performance indicators at each touchpoint, helping identify both strengths and opportunities for improvement in the user experience. Using speech to text ai tools can enhance these user journeys by supporting multimodal interaction patterns.
Building Evaluation Infrastructure
For ongoing LLM evaluation, I set up monitoring dashboards that track performance metrics over time. These dashboards provide visibility into how models are performing in production, helping identify any degradation or drift that might require attention.
Version control for evaluation datasets and benchmarks is crucial in my infrastructure. As models and requirements evolve, maintaining consistent evaluation standards requires careful management of test data and metrics definitions.
flowchart TD
A[Evaluation Infrastructure] --> B[Monitoring System]
A --> C[Data Management]
A --> D[Collaboration Tools]
A --> E[Documentation Platform]
B --> B1[Real-time Dashboards]
B --> B2[Alert Mechanisms]
B --> B3[Performance Tracking]
B --> B4[Usage Analytics]
C --> C1[Test Dataset Repository]
C --> C2[Benchmark Version Control]
C --> C3[Result History Database]
C --> C4[Evaluation Metadata]
D --> D1[Cross-functional Workflows]
D --> D2[Review Processes]
D --> D3[Decision Documentation]
D --> D4[Feedback Integration]
E --> E1[Evaluation Protocols]
E --> E2[Model Cards]
E --> E3[Performance Reports]
E --> E4[Compliance Documentation]
style A fill:#FF8000,stroke:#333,stroke-width:2px
I develop collaborative evaluation workflows that span technical and business teams. This ensures that both technical performance and business requirements are considered in the evaluation process, leading to more holistic assessments and better-aligned decisions.
Documentation standards are essential for evaluation findings. I create structured templates for recording test results, decisions made, and their rationales, ensuring knowledge is preserved and accessible even as team members change over time.
To visualize evaluation infrastructure concepts, I use PageOn.ai to transform abstract architectures into clear system diagrams. These visual representations help stakeholders understand how different components of the evaluation system work together and support ongoing model assessment and improvement. For presentations, best ai text to speech tool options can help narrate these complex infrastructures.
Case Studies in LLM Selection Success
I've analyzed numerous enterprise implementation stories across diverse industries, from healthcare organizations using LLMs for medical documentation to financial institutions implementing models for risk assessment. These case studies reveal patterns in successful selection processes.
Key decision factors that consistently lead to successful model selections include:
- Alignment with specific use case requirements rather than choosing the most advanced or newest model
- Rigorous testing in environments that closely mimic production conditions
- Careful consideration of operational constraints like latency requirements and budget limitations
- Involvement of end-users in the evaluation and selection process
- Clear governance frameworks for ongoing monitoring and evaluation
I've also identified common pitfalls to avoid, such as:
- Over-indexing on benchmark performance without considering real-world application needs
- Inadequate testing of edge cases and failure modes
- Insufficient attention to ethical considerations and potential biases
- Underestimating integration complexity and total cost of ownership
- Lack of clear success metrics and evaluation criteria
ROI Comparison: Before vs After LLM Implementation
Results from successful enterprise implementations:
Before-and-after scenarios demonstrate the impact of successful LLM implementations. For example, I've documented cases where customer support resolution times decreased by 65% after implementing a well-selected LLM, and content creation workflows that became 3x more efficient.
To communicate these success stories effectively, I use PageOn.ai to craft visual narratives of evaluation journeys and outcomes. These visualizations help stakeholders understand not just the end results but the entire process that led to successful model selection and implementation.

Future-Proofing Your LLM Strategy
The LLM landscape is evolving rapidly, so I create evaluation frameworks that accommodate emerging model capabilities. These frameworks have built-in flexibility to assess new features like multimodal inputs, enhanced reasoning, or improved factuality as they become available.
I build adaptable testing protocols that can evolve with LLM architectures. Rather than hardcoding specific expectations, these protocols focus on outcomes and can be updated as new model architectures emerge with different strengths and limitations.
LLM Capability Evolution Projection
Anticipated progress in key capability areas:
Competitive benchmarking processes help me stay aware of new market entrants and their capabilities. By regularly evaluating emerging models against established benchmarks, I can identify when new options might offer significant advantages over current selections.
Scenario planning for LLM technology evolution is another strategy I employ. This involves anticipating potential shifts in the landscape (like the emergence of new architectures or significant capability breakthroughs) and developing contingency plans for how evaluation and selection processes might need to adapt.
To visualize these forward-looking considerations, I use PageOn.ai to create technology roadmaps and future evaluation frameworks. These visualizations help stakeholders understand how the organization's LLM strategy can evolve alongside the technology, ensuring continued alignment with business goals as capabilities advance.
Transform Your LLM Evaluation Process with PageOn.ai
Turn complex model assessments into clear visual frameworks that drive better decisions and align stakeholders. Start creating powerful evaluation visualizations today.
Start Creating with PageOn.ai TodayConclusion
Evaluating and selecting the right LLM for your project is a multifaceted process that requires careful consideration of technical performance, ethical implications, practical constraints, and business alignment. By implementing the structured evaluation frameworks and visualization approaches outlined in this guide, you can make more informed decisions and select models that truly meet your needs.
Remember that LLM evaluation is not a one-time activity but an ongoing process. As models evolve and your requirements change, regular reassessment ensures your LLM strategy remains effective and aligned with your goals.
Throughout this journey, visualization tools like PageOn.ai can transform complex evaluation data into clear, actionable insights that drive better decisions and foster alignment across technical and business teams. By making the invisible visible, these tools help ensure that your LLM selection process is both rigorous and accessible to all stakeholders.
You Might Also Like
The AI Superpower Timeline: Visualizing US-China AI Race & Tech Developments
Explore the narrowing US-China AI performance gap, historical milestones, technical battlegrounds, and future projections in the global artificial intelligence race through interactive visualizations.
How 85% of Marketers Transform Content Strategy with AI Visual Tools | PageOn.ai
Discover how 85% of marketers are revolutionizing content strategy with AI tools, saving 3 hours per piece while improving quality and output by 82%.
The Meta-Mind Advantage: How Self-Aware AI Strategy Defines Market Leadership in 2025
Discover why metacognitive AI strategy separates industry leaders from followers in 2025. Learn frameworks for building self-aware AI implementation that drives competitive advantage.
First Principles Framework for Building Powerful AI Commands | Master AI Prompt Engineering
Learn the first principles approach to crafting powerful AI commands. Master prompt engineering with proven frameworks, templates, and visualization techniques for optimal AI interaction.