Building Powerful Real-World AI Applications with PostgreSQL and Claude
A comprehensive guide to integrating database power with AI intelligence
Understanding the Foundation: PostgreSQL and Claude AI Integration
I've spent years working with database systems and AI models, and I can confidently say that the combination of PostgreSQL and Claude represents a powerful new paradigm for building intelligent applications. This integration creates a foundation where structured data management meets advanced AI capabilities, opening up possibilities that weren't previously feasible with separate systems.
At the core of this integration is the pgai extension, which creates a seamless bridge between PostgreSQL's robust data management capabilities and Claude's advanced language processing. This combination allows developers to build applications that leverage both structured data and AI intelligence within a unified architecture.
Key Benefits of PostgreSQL + Claude Integration
flowchart TD
A[PostgreSQL + Claude Integration] --> B[Data Proximity]
A --> C[Reduced Latency]
A --> D[Simplified Architecture]
A --> E[Cost Efficiency]
B --> B1[AI operations closer to data]
B --> B2[Reduced data movement]
C --> C1[Fewer API round trips]
C --> C2[Faster response times]
D --> D1[Unified management]
D --> D2[Fewer integration points]
E --> E1[Optimized token usage]
E --> E2[Reduced infrastructure costs]
style A fill:#FF8000,stroke:#333,stroke-width:2px,color:white
style B fill:#42A5F5,stroke:#333,stroke-width:1px
style C fill:#42A5F5,stroke:#333,stroke-width:1px
style D fill:#42A5F5,stroke:#333,stroke-width:1px
style E fill:#42A5F5,stroke:#333,stroke-width:1px
The key benefits of this integration include keeping AI operations closer to your data, which significantly reduces latency by minimizing data movement. The architecture becomes simpler, with fewer moving parts and integration points to manage. In my experience working with these technologies, this approach leads to more maintainable and reliable applications.
Modern AI applications require both reliable data storage and intelligent processing capabilities. By bringing Claude's capabilities directly into PostgreSQL, we can create applications that are both data-rich and intelligently responsive. This foundation is what makes sophisticated use cases like semantic search, natural language querying, and AI assistants possible within a single, cohesive system.
Setting Up Your Development Environment
Before diving into application development, we need to establish a solid development environment. I'll walk you through the essential components and setup steps I've found most effective for PostgreSQL and Claude integration projects.
Installing PostgreSQL with Necessary Extensions
For rapid development, I prefer using Docker to set up PostgreSQL with all the required extensions. This approach ensures consistency across development environments and simplifies deployment.
docker pull timescale/timescaledb:latest-pg15
docker run -d --name postgres-ai \
-e POSTGRES_PASSWORD=mysecretpassword \
-p 5432:5432 \
timescale/timescaledb:latest-pg15
psql -h localhost -U postgres -d postgres
After connecting to PostgreSQL, we need to install the pgai and pgvector extensions, which are essential for AI operations and vector embeddings respectively:
-- Inside PostgreSQL
CREATE EXTENSION pgai;
CREATE EXTENSION vector;
-- Verify installation
\dx
Configuring Claude API Access
To integrate Claude with our PostgreSQL database, we need to set up API access through the Anthropic Console. Security is paramount when handling API keys, so I always recommend using environment variables for storage rather than hardcoding them in your application.

Once you have your API key from the Anthropic Console, you can configure pgai to use it:
export PGOPTIONS="-c ai.anthropic_api_key=$ANTHROPIC_API_KEY"
SET ai.anthropic_api_key = 'your_api_key_here';
Essential Tools and Libraries
For effective development, you'll need several Python libraries to connect your application code with PostgreSQL and Claude:
pip install psycopg2 # PostgreSQL connector
pip install anthropic # Claude API client
When implementing open source AI tools with PostgreSQL and Claude, I've found that maintaining a clear separation of concerns in your codebase makes development and maintenance much easier. Using environment management tools like conda or venv helps ensure consistency across different development environments.
Core Architecture Patterns for PostgreSQL-Claude Applications
The integration of PostgreSQL and Claude enables several powerful architectural patterns that form the foundation of modern AI applications. I've implemented these patterns across various projects and found them to be highly effective.
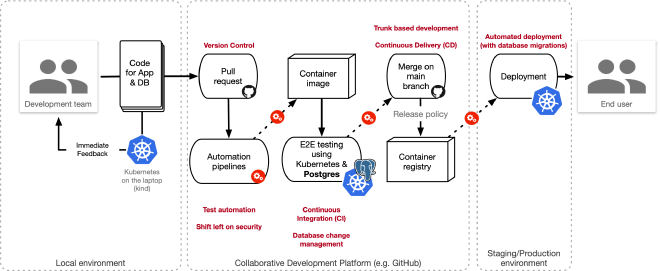
In-database AI Processing Model
One of the most transformative patterns is the in-database AI processing model, where AI operations are executed directly within PostgreSQL using the pgai extension. This approach offers significant advantages over traditional architectures that separate database and AI processing.
Traditional vs. In-Database AI Architecture
flowchart TD
subgraph "Traditional Architecture"
DB1[PostgreSQL Database] --> |Raw Data| APP[Application Server]
APP --> |Data| AI[External AI Service]
AI --> |Results| APP
APP --> |Processed Data| DB1
end
subgraph "In-Database AI Architecture"
DB2[PostgreSQL Database] --> |Direct Function Call| PGAI[pgai Extension]
PGAI --> |API Call| CLAUDE[Claude API]
CLAUDE --> |Results| PGAI
PGAI --> |Processed Data| DB2
end
With the in-database approach, we eliminate the need to move large amounts of data between the database and application server. This reduces latency, simplifies the architecture, and improves security by keeping sensitive data within the database environment.
Here's a simple example of using pgai to generate content directly within PostgreSQL:
-- Generate a product description based on features
SELECT ai.completion(
'claude-3-opus-20240229',
'Write a concise product description for a smartphone with the following features: ' ||
string_agg(feature, ', ') AS description
FROM product_features
WHERE product_id = 123;
Vector Embeddings and Semantic Search
Another powerful pattern is leveraging pgvector for efficient vector operations, enabling semantic search capabilities directly within PostgreSQL. This approach allows us to find content based on meaning rather than just keywords.
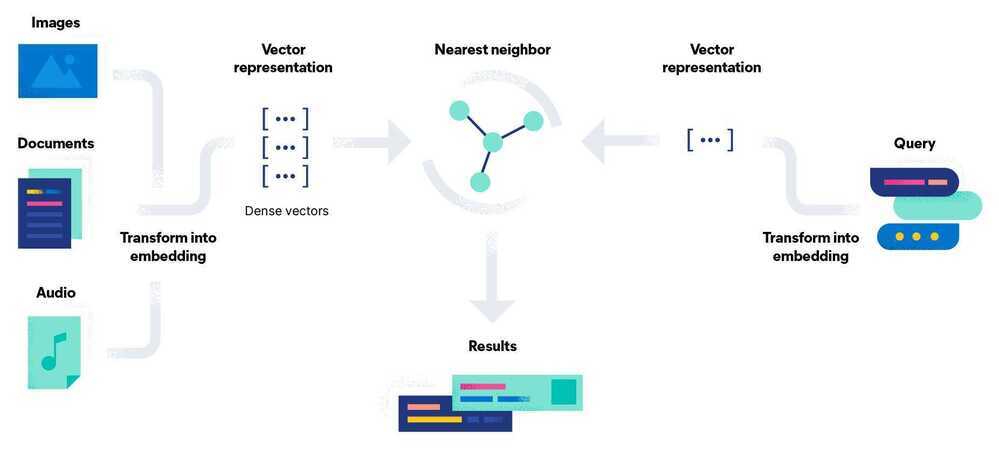
Creating and storing embeddings is straightforward with pgai and pgvector:
-- Create a table with vector column
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536) -- Dimension matches Claude's embeddings
);
-- Generate embedding for a document
INSERT INTO documents (content, embedding)
SELECT
'PostgreSQL is a powerful open-source relational database system.',
ai.embedding('claude', 'PostgreSQL is a powerful open-source relational database system.');
-- Perform semantic search
SELECT content, 1 - (embedding <=> ai.embedding('claude', 'database systems')) AS similarity
FROM documents
ORDER BY similarity DESC
LIMIT 5;
Retrieval Augmented Generation (RAG) Architecture
RAG combines traditional search with vector-based retrieval to enhance AI responses with relevant information from your database. This architecture is particularly effective for building AI agents that can access and reason about specific knowledge bases.
RAG Architecture Flow
flowchart TD
Q[User Query] --> EMB[Generate Query Embedding]
EMB --> RETR[Retrieve Relevant Documents]
RETR --> |Vector Similarity| VEC[Vector Search]
RETR --> |Keywords| KEY[Keyword Search]
DB[(PostgreSQL Database)] --> VEC
DB --> KEY
VEC --> COMB[Combine Results]
KEY --> COMB
COMB --> AUG[Augment Prompt with Context]
AUG --> GEN[Generate Response with Claude]
GEN --> RESP[Final Response]
style Q fill:#FF8000,stroke:#333,stroke-width:1px
style RESP fill:#FF8000,stroke:#333,stroke-width:1px
style DB fill:#42A5F5,stroke:#333,stroke-width:1px
style GEN fill:#66BB6A,stroke:#333,stroke-width:1px
Implementing a hybrid retrieval system that combines BM25 (keyword-based) and vector search gives us the best of both worlds. This approach reduces hallucinations by grounding Claude's responses in factual information from our database.
-- Hybrid search function combining BM25 and vector similarity
CREATE OR REPLACE FUNCTION hybrid_search(query_text TEXT, limit_val INT DEFAULT 5)
RETURNS TABLE (id INT, content TEXT, score FLOAT) AS $$
BEGIN
RETURN QUERY
WITH bm25_results AS (
SELECT id, content, ts_rank(to_tsvector('english', content), to_tsquery('english', query_text)) AS bm_score
FROM documents
WHERE to_tsvector('english', content) @@ to_tsquery('english', query_text)
),
vector_results AS (
SELECT id, content, 1 - (embedding <=> ai.embedding('claude', query_text)) AS vec_score
FROM documents
)
SELECT b.id, b.content, (b.bm_score * 0.4 + v.vec_score * 0.6) AS combined_score
FROM bm25_results b
JOIN vector_results v ON b.id = v.id
ORDER BY combined_score DESC
LIMIT limit_val;
END;
$$ LANGUAGE plpgsql;
Building Real-World Applications: Practical Implementation
Now that we understand the core architecture patterns, let's explore how to implement real-world applications that leverage PostgreSQL and Claude. I'll share practical examples from my experience building these systems.
Intelligent Data Processing Applications
One of the most valuable use cases I've implemented is automated data classification and enrichment. This allows systems to categorize incoming data and enhance it with AI-generated insights.
Data Classification Performance Comparison
Implementing natural language querying of database content is another powerful application. This allows users to interact with data using conversational language rather than complex SQL queries.
-- Function to translate natural language to SQL
CREATE OR REPLACE FUNCTION natural_language_to_sql(question TEXT)
RETURNS TABLE (sql_query TEXT, explanation TEXT) AS $$
DECLARE
result RECORD;
BEGIN
-- Get table information for context
WITH table_info AS (
SELECT
t.tablename,
string_agg(a.attname || ' (' || pg_catalog.format_type(a.atttypid, a.atttypmod) || ')', ', ') AS columns
FROM pg_catalog.pg_tables t
JOIN pg_catalog.pg_class c ON t.tablename = c.relname
JOIN pg_catalog.pg_attribute a ON c.oid = a.attrelid
WHERE t.schemaname = 'public' AND a.attnum > 0 AND NOT a.attisdropped
GROUP BY t.tablename
)
-- Use Claude to generate SQL
SELECT
(ai.completion_object(
'claude-3-opus-20240229',
'You are an expert SQL translator. Convert this question to a PostgreSQL SQL query.
Available tables and their columns:
' || string_agg(tablename || ': ' || columns, '\n') || '
Question: ' || question || '
Return a JSON object with these fields:
- sql_query: The PostgreSQL query that answers the question
- explanation: A brief explanation of how the query works
Ensure the SQL is valid PostgreSQL syntax.',
'{"response_format": {"type": "json_object"}}'
)).content::json INTO result
FROM table_info;
RETURN QUERY SELECT
result->>'sql_query' AS sql_query,
result->>'explanation' AS explanation;
END;
$$ LANGUAGE plpgsql;
This function leverages Claude's understanding of both natural language and SQL to translate user questions into executable queries. The system becomes more powerful when combined with a feedback loop that improves translations over time.
AI-Powered Search Applications
Building sophisticated search experiences that combine keyword search with semantic understanding is one of the most impactful applications of this technology stack. I've implemented several systems that deliver personalized search results based on user context.

Product search optimization is particularly valuable for e-commerce applications. By understanding product attributes semantically, we can handle synonyms and related terms intelligently:
-- Enhanced product search with semantic understanding
CREATE OR REPLACE FUNCTION semantic_product_search(search_query TEXT, category_filter TEXT DEFAULT NULL)
RETURNS TABLE (
product_id INT,
product_name TEXT,
description TEXT,
price NUMERIC,
relevance_score FLOAT,
match_reason TEXT
) AS $$
DECLARE
query_embedding VECTOR(1536);
BEGIN
-- Generate embedding for search query
query_embedding := ai.embedding('claude', search_query);
RETURN QUERY
WITH semantic_matches AS (
SELECT
p.id,
p.name,
p.description,
p.price,
1 - (p.feature_embedding <=> query_embedding) AS semantic_score
FROM products p
WHERE category_filter IS NULL OR p.category = category_filter
),
keyword_matches AS (
SELECT
p.id,
p.name,
p.description,
p.price,
ts_rank(to_tsvector('english', p.name || ' ' || p.description),
plainto_tsquery('english', search_query)) AS keyword_score
FROM products p
WHERE
to_tsvector('english', p.name || ' ' || p.description) @@
plainto_tsquery('english', search_query)
AND (category_filter IS NULL OR p.category = category_filter)
),
combined_results AS (
SELECT
COALESCE(s.id, k.id) AS id,
COALESCE(s.name, k.name) AS name,
COALESCE(s.description, k.description) AS description,
COALESCE(s.price, k.price) AS price,
COALESCE(s.semantic_score, 0) * 0.7 + COALESCE(k.keyword_score, 0) * 0.3 AS combined_score,
CASE
WHEN s.semantic_score > 0.8 THEN 'Strong semantic match'
WHEN k.keyword_score > 0.8 THEN 'Strong keyword match'
ELSE 'Partial match'
END AS match_reason
FROM semantic_matches s
FULL OUTER JOIN keyword_matches k ON s.id = k.id
)
SELECT * FROM combined_results
WHERE combined_score > 0.3
ORDER BY combined_score DESC
LIMIT 20;
END;
$$ LANGUAGE plpgsql;
Interactive AI Agents
Creating database-aware AI assistants is where the integration of PostgreSQL and Claude truly shines. These agents can query and update database data while maintaining a conversational interface with users.
Interactive AI Agent Architecture
flowchart TD
U[User] <-->|Natural Language| I[Interface Layer]
I <-->|Structured Request| A[AI Agent]
A <-->|Database Operations| DB[(PostgreSQL)]
A <-->|Memory & Context| M[Agent Memory]
subgraph "Agent Components"
A --> P[Prompt Management]
A --> T[Tool Selection]
A --> V[Data Validation]
A --> R[Response Generation]
end
M -->|Previous Interactions| A
DB -->|Data Schema| A
style U fill:#FF8000,stroke:#333,stroke-width:1px
style DB fill:#42A5F5,stroke:#333,stroke-width:1px
style A fill:#66BB6A,stroke:#333,stroke-width:1px
style M fill:#E57373,stroke:#333,stroke-width:1px
Implementing memory and context management is crucial for creating agents that maintain coherent conversations. I've found that storing conversation history in PostgreSQL allows for efficient context retrieval and persistence across sessions.
-- Agent memory schema
CREATE TABLE agent_conversations (
conversation_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id TEXT NOT NULL,
created_at TIMESTAMP WITH TIME ZONE DEFAULT now(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT now()
);
CREATE TABLE agent_messages (
message_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
conversation_id UUID REFERENCES agent_conversations(conversation_id),
role TEXT NOT NULL CHECK (role IN ('user', 'assistant', 'system')),
content TEXT NOT NULL,
timestamp TIMESTAMP WITH TIME ZONE DEFAULT now(),
embedding VECTOR(1536) GENERATED ALWAYS AS (
CASE WHEN role IN ('user', 'assistant')
THEN ai.embedding('claude', content)
ELSE NULL
END
) STORED
);
-- Create index for semantic search on message content
CREATE INDEX ON agent_messages USING hnsw (embedding vector_cosine_ops);
With this foundation, we can implement multi-agent systems for complex workflows, where specialized agents handle different tasks while coordinating through a shared database. This approach enables sophisticated AI implementation strategies that can adapt to complex business requirements.
Advanced Features and Optimization
As we move from development to production, optimization becomes critical. I'll share strategies I've developed for performance tuning, security considerations, and cost optimization.
Performance Tuning for Production Environments
Database indexing strategies are particularly important for AI workloads, which often involve complex queries across large datasets. Vector indexes require special attention:
-- Create HNSW index for faster vector similarity search
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops)
WITH (
ef_construction = 128, -- Higher values = better quality but slower build
m = 16 -- Number of connections per node
);
Caching mechanisms for frequently accessed data can dramatically improve performance. I've implemented a tiered caching strategy that stores common queries and their results:
Query Performance with Different Optimization Techniques
Security and Compliance Considerations
Data protection strategies are essential when using AI, particularly for sensitive information. I implement row-level security policies in PostgreSQL to ensure data access controls are enforced:
-- Enable row-level security
ALTER TABLE customer_data ENABLE ROW LEVEL SECURITY;
-- Create policy that restricts access based on user role
CREATE POLICY customer_data_access ON customer_data
USING (
current_user = 'admin' OR
(current_user = 'support' AND sensitivity_level <= 2) OR
(created_by = current_user)
);
-- Function to redact sensitive data before sending to Claude
CREATE OR REPLACE FUNCTION redact_sensitive_data(text_content TEXT)
RETURNS TEXT AS $$
DECLARE
redacted TEXT;
BEGIN
-- Redact credit card numbers
redacted := regexp_replace(text_content,
'([0-9]{4})[0-9]{8}([0-9]{4})',
'\1********\2',
'g');
-- Redact email addresses
redacted := regexp_replace(redacted,
'([a-zA-Z0-9._%+-]+)@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})',
'\1@*****',
'g');
RETURN redacted;
END;
$$ LANGUAGE plpgsql;
Audit trails and monitoring are crucial for AI operations. I create comprehensive logging mechanisms that track all AI interactions:
-- Create audit log table
CREATE TABLE ai_operation_logs (
log_id SERIAL PRIMARY KEY,
operation_type TEXT NOT NULL,
user_id TEXT NOT NULL,
prompt_summary TEXT NOT NULL,
prompt_tokens INT,
completion_tokens INT,
total_cost NUMERIC(10,6),
execution_time INTERVAL,
timestamp TIMESTAMP WITH TIME ZONE DEFAULT now()
);
-- Trigger to automatically log AI operations
CREATE OR REPLACE FUNCTION log_ai_operation()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO ai_operation_logs (
operation_type,
user_id,
prompt_summary,
prompt_tokens,
completion_tokens,
total_cost,
execution_time
) VALUES (
TG_ARGV[0],
current_user,
left(NEW.prompt, 100) || '...',
NEW.prompt_tokens,
NEW.completion_tokens,
(NEW.prompt_tokens * 0.00001 + NEW.completion_tokens * 0.00003),
NEW.execution_time
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Cost Optimization Techniques
Managing API usage costs is essential for production applications. I've developed several strategies to reduce token usage without compromising quality:
Token Usage Optimization Strategies
flowchart TD
A[Token Usage Optimization] --> B[Prompt Engineering]
A --> C[Caching Strategies]
A --> D[Model Selection]
A --> E[Context Pruning]
B --> B1[Concise Instructions]
B --> B2[Structured Output Formats]
C --> C1[Response Caching]
C --> C2[Embedding Caching]
D --> D1[Right-sizing Models]
D --> D2[Task-specific Models]
E --> E1[Relevant Context Selection]
E --> E2[Context Summarization]
style A fill:#FF8000,stroke:#333,stroke-width:2px,color:white
Implementing these optimization techniques can lead to significant cost savings. In my projects, I've seen token usage reductions of 40-60% while maintaining or even improving response quality.
Balancing performance and cost considerations requires careful monitoring and adjustment. I recommend implementing dashboards that track both performance metrics and cost metrics, allowing you to make data-driven decisions about optimizations.
Case Studies and Real-World Examples
Let's examine some real-world implementations that demonstrate the power of PostgreSQL and Claude integration. These case studies illustrate practical applications and implementation details.
Financial Information Platform
One of the most impressive implementations I've seen is a financial information platform that uses PostgreSQL and Claude to analyze market data and generate insights. This system processes vast amounts of financial news, reports, and market data to provide actionable intelligence.

The architecture combines real-time market data with natural language processing to identify trends and generate reports. PostgreSQL's time-series capabilities (via TimescaleDB) handle the quantitative data, while Claude analyzes qualitative information from news sources and company reports.
Key performance metrics from this implementation include:
Financial Platform Performance Metrics
Weather Query AI Agent
Another interesting example is a weather query AI agent that combines PostgreSQL, Claude, and the OpenWeatherMap API. This system demonstrates how external data sources can be integrated with our database and AI architecture.
-- Create table for caching weather data
CREATE TABLE weather_cache (
location_name TEXT PRIMARY KEY,
weather_data JSONB NOT NULL,
last_updated TIMESTAMP WITH TIME ZONE DEFAULT now()
);
-- Function to fetch weather data with caching
CREATE OR REPLACE FUNCTION get_weather(location TEXT)
RETURNS JSONB AS $$
DECLARE
cache_record RECORD;
api_response JSONB;
api_key TEXT := current_setting('app.openweathermap_key');
BEGIN
-- Check cache first
SELECT * INTO cache_record
FROM weather_cache
WHERE location_name = location AND last_updated > (now() - interval '30 minutes');
-- Return cached data if available and recent
IF FOUND THEN
RETURN cache_record.weather_data;
END IF;
-- Fetch from API if not in cache or expired
SELECT content::jsonb INTO api_response
FROM http_get('https://api.openweathermap.org/data/2.5/weather?q=' ||
location || '&appid=' || api_key || '&units=metric');
-- Update cache
INSERT INTO weather_cache (location_name, weather_data)
VALUES (location, api_response)
ON CONFLICT (location_name)
DO UPDATE SET weather_data = api_response, last_updated = now();
RETURN api_response;
END;
$$ LANGUAGE plpgsql;
-- Function to generate natural language weather report
CREATE OR REPLACE FUNCTION weather_report(location TEXT)
RETURNS TEXT AS $$
DECLARE
weather_data JSONB;
BEGIN
-- Get weather data
weather_data := get_weather(location);
-- Generate natural language report using Claude
RETURN ai.completion(
'claude-3-sonnet-20240229',
'Create a brief, friendly weather report for ' || location || ' based on this data: ' ||
weather_data::text ||
'Include temperature, conditions, and any notable weather features in a conversational tone.'
);
END;
$$ LANGUAGE plpgsql;
This weather agent demonstrates several important patterns: external API integration, caching for performance and cost optimization, and natural language generation based on structured data. The system provides a conversational interface to weather information while efficiently managing API usage.
Customer Support Enhancement with RAG
A particularly effective implementation I've worked on is a customer support system that uses RAG to enhance responses with knowledge base information. This system dramatically improved response quality and reduced the need for escalations.
Customer Support RAG System Architecture
flowchart TD
Q[Customer Query] --> NLP[Query Analysis]
NLP --> |Extract Intent| INT[Intent Classification]
NLP --> |Extract Entities| ENT[Entity Recognition]
INT --> RET[Knowledge Retrieval]
ENT --> RET
RET --> |Vector Search| KB[(Knowledge Base)]
KB --> AUG[Context Augmentation]
AUG --> GEN[Response Generation]
GEN --> RES[Customer Response]
RES --> |Feedback Loop| FB[Quality Monitoring]
FB --> |Update| KB
style Q fill:#FF8000,stroke:#333,stroke-width:1px
style RES fill:#FF8000,stroke:#333,stroke-width:1px
style KB fill:#42A5F5,stroke:#333,stroke-width:1px
style GEN fill:#66BB6A,stroke:#333,stroke-width:1px
The system incorporates a feedback loop that continuously improves response quality by tracking customer satisfaction and agent interventions. This approach allows the system to learn from experience and become more effective over time.
Implementing AI-powered app integration strategies like this customer support system requires careful attention to both technical implementation and user experience design. The most successful systems combine powerful backend capabilities with intuitive interfaces.
Future Directions and Emerging Patterns
As we look to the future, several exciting trends are emerging in the space of database-integrated AI applications. I'm particularly interested in how these technologies will evolve to enable even more sophisticated systems.
Evolving Trends in Database-Integrated AI
We're moving beyond basic RAG architectures to more sophisticated approaches that combine multiple retrieval strategies and reasoning capabilities. These systems can handle more complex queries and provide more nuanced responses.
Evolution of AI Database Integration
Another interesting trend is the combination of multiple AI models for specialized tasks. This approach allows systems to leverage the strengths of different models while mitigating their weaknesses. For example, using specialized models for code generation, data analysis, and natural language generation within a single application.
Visualizing AI Application Results with PageOn.ai
One of the most exciting developments I've been exploring is using PageOn.ai to transform complex AI outputs into clear visual formats. This approach makes the insights generated by AI systems more accessible and actionable for users.
Using AI Blocks to structure database query results is particularly powerful. This approach allows us to create modular visualizations that can be combined and customized to meet specific needs. PageOn.ai's intuitive interface makes it easy to transform complex data into clear visual expressions.
Creating dynamic dashboards from PostgreSQL data becomes remarkably straightforward with these tools. The combination of PostgreSQL's powerful query capabilities, Claude's natural language understanding, and PageOn.ai's visualization tools creates a comprehensive solution for data-driven decision making.
Building Collaborative AI Systems
Human-in-the-loop workflows represent another important direction for PostgreSQL and Claude integration. These systems combine the efficiency of automation with the judgment and creativity of human experts.
Human-in-the-Loop Workflow
flowchart TD
START[User Request] --> AI[AI Processing]
AI --> CONF{Confidence Check}
CONF -->|High Confidence| AUTO[Automated Response]
CONF -->|Low Confidence| HUMAN[Human Review]
AUTO --> FEED[Feedback Collection]
HUMAN --> FEED
FEED --> LEARN[Learning System]
LEARN --> DB[(PostgreSQL Knowledge Base)]
DB --> AI
style START fill:#FF8000,stroke:#333,stroke-width:1px
style HUMAN fill:#E57373,stroke:#333,stroke-width:1px
style DB fill:#42A5F5,stroke:#333,stroke-width:1px
style LEARN fill:#66BB6A,stroke:#333,stroke-width:1px
Implementing feedback mechanisms to improve system performance is crucial for these collaborative systems. By tracking user interactions and outcomes, we can continuously refine both the AI models and the database structures that support them.
Balancing automation with human oversight requires careful design and ongoing monitoring. The most effective systems provide appropriate levels of transparency and control, allowing human experts to understand and guide AI operations effectively.
Conclusion and Resources
Throughout this guide, we've explored the powerful combination of PostgreSQL and Claude for building sophisticated AI applications. This integration offers a unique approach that keeps AI operations close to your data, reducing complexity while enhancing capabilities.
Key Takeaways for Successful Implementation
Keep AI Close to Data
Use pgai to perform AI operations directly within PostgreSQL, minimizing data movement and latency.
Implement Hybrid Search
Combine vector and keyword search for more robust and accurate retrieval capabilities.
Optimize for Performance and Cost
Use proper indexing, caching, and token management strategies to balance efficiency and expenses.
Prioritize Security and Compliance
Implement row-level security, data redaction, and comprehensive audit logging for AI operations.
Common pitfalls to avoid include neglecting proper indexing for vector searches, which can lead to performance degradation as your data grows. Another frequent issue is failing to implement appropriate caching strategies, resulting in unnecessary API calls and increased costs. Finally, inadequate error handling can lead to brittle applications that fail in unexpected ways when AI services encounter problems.
Community Resources and Further Learning
To continue your journey with PostgreSQL and Claude integration, I recommend exploring these resources:
- The pgai GitHub repository for documentation and examples
- Anthropic's Claude API documentation and cookbook
- The PostgreSQL community forums for database optimization techniques
- TimescaleDB documentation for time-series data handling
Getting Started with Your First Application
To begin building your own PostgreSQL and Claude application, start with a simple project that implements the core patterns we've discussed. Here's a simplified starter template that you can expand upon:
-- 1. Set up your database schema
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT NOT NULL,
embedding VECTOR(1536) GENERATED ALWAYS AS (ai.embedding('claude', content)) STORED
);
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- 2. Create a basic RAG function
CREATE OR REPLACE FUNCTION answer_question(question TEXT)
RETURNS TEXT AS $$
DECLARE
context TEXT;
answer TEXT;
BEGIN
-- Retrieve relevant context
SELECT string_agg(content, '\n\n')
INTO context
FROM (
SELECT content
FROM documents
ORDER BY embedding <=> ai.embedding('claude', question)
LIMIT 3
) relevant_docs;
-- Generate answer using Claude
answer := ai.completion(
'claude-3-sonnet-20240229',
'Answer the question based on the provided context. If the context doesn''t contain ' ||
'relevant information, say "I don''t have enough information to answer that question."
Context:
' || context || '
Question: ' || question
);
RETURN answer;
END;
$$ LANGUAGE plpgsql;
Testing and validation are critical aspects of AI application development. I recommend implementing automated tests that verify both the functional correctness and the quality of AI responses. This approach ensures that your application remains reliable as you continue to develop and refine it.
Transform Your Visual Expressions with PageOn.ai
Turn your complex PostgreSQL and Claude AI outputs into stunning visualizations that communicate insights clearly and effectively.
Start Creating with PageOn.ai TodayAs you continue to explore the possibilities of PostgreSQL and Claude integration, remember that the most successful applications are those that solve real problems for users. Focus on delivering value through clear insights, efficient workflows, and intuitive interfaces.
I hope this guide has provided you with a solid foundation for building your own AI applications with PostgreSQL and Claude. The combination of robust data management and advanced AI capabilities opens up exciting possibilities for innovation across many domains.
You Might Also Like
Transform Your Google Slides: Advanced Techniques for Polished Presentations
Master advanced Google Slides techniques for professional presentations. Learn design fundamentals, visual enhancements, Slide Master, and interactive elements to create stunning slides.
Mastering Visual Flow: How Morph Transitions Transform Presentations | PageOn.ai
Discover how Morph transitions create dynamic, seamless visual connections between slides, enhancing audience engagement and transforming ordinary presentations into memorable experiences.
The AI-Powered Pitch Deck Revolution: A Three-Step Framework for Success
Discover the three-step process for creating compelling AI-powered pitch decks that captivate investors. Learn how to clarify your vision, structure your pitch, and refine for maximum impact.
Revolutionizing Slides: The Power of AI Presentation Tools | PageOn.ai
Discover how AI presentation tools are transforming slide creation, saving hours of work while enhancing design quality. Learn how PageOn.ai can help visualize your ideas instantly.