Visualizing the AI Agent Testing Landscape
A Comprehensive Benchmark Performance Comparison
The Evolution of AI Agent Testing Frameworks
I've watched the AI agent testing landscape evolve dramatically over the years. What began as simple evaluations of language model outputs has transformed into sophisticated frameworks for assessing multi-modal, multi-step agent behaviors in complex environments.
timeline
title Evolution of AI Agent Benchmarking
2018 : Simple LLM Evaluations
: Focused on text generation quality
: Static prompts and responses
2020 : Task-Specific Benchmarks
: GLUE, SuperGLUE
: Isolated capabilities testing
2022 : Early Agent Frameworks
: ReAct patterns
: Tool-use evaluation
2023 : Multi-step Reasoning
: Chain-of-thought evaluation
: Function calling assessment
2024 : Real-world Simulations
: Multi-turn conversations
: Dynamic environments
2025 : Standardized Agent Benchmarks
: Universal metrics
: Multi-modal testing
The historical development of benchmarking methodologies shows a clear trajectory from isolated tasks to comprehensive real-world simulations. Early benchmarks focused primarily on language understanding and generation quality, while today's frameworks assess complex reasoning, tool utilization, and multi-step decision-making.
One of the most significant challenges I encounter in this field is the standardization of performance metrics across different frameworks. With ai model benchmarking becoming increasingly complex, organizations struggle to compare results meaningfully across different testing environments.
When working with complex benchmark data, I've found that visual representations are essential for stakeholder understanding. PageOn.ai transforms dense performance metrics into clear, intuitive visualizations that highlight patterns and insights that might otherwise remain hidden in numerical tables.

Leading AI Agent Testing Frameworks in 2025
As we navigate the complex landscape of AI agent evaluation, several frameworks have emerged as leaders in the field. Each offers unique approaches to testing different aspects of agent performance.
AgentBench
AgentBench stands out as a comprehensive evaluation suite specifically designed for language agents. I've used this framework extensively to assess decision-making capabilities, reasoning patterns, and tool usage effectiveness across different agent architectures.
flowchart TD
AB[AgentBench] --> DM[Decision Making]
AB --> RA[Reasoning Assessment]
AB --> TU[Tool Usage]
DM --> DM1[Strategic Planning]
DM --> DM2[Resource Allocation]
DM --> DM3[Prioritization Logic]
RA --> RA1[Chain-of-Thought]
RA --> RA2[Logical Consistency]
RA --> RA3[Error Detection]
TU --> TU1[API Integration]
TU --> TU2[Tool Selection]
TU --> TU3[Parameter Configuration]
classDef orange fill:#FF8000,stroke:#333,stroke-width:1px;
class AB orange
AgentBench employs a multi-dimensional scoring system that evaluates agents across various capabilities. Using PageOn.ai's AI Blocks, I can visualize these dimensions to identify specific areas where agents excel or need improvement.
τ-Bench Framework
The τ-Bench framework represents a significant advancement in AI agent testing by focusing on realistic human-agent interactions with programmatic APIs. What makes this framework particularly valuable is its emphasis on domain-specific policy compliance.

According to recent research from Sierra's τ-Bench analysis, even the most advanced agents like GPT-4o achieve less than 50% average success rates across multiple domains in these realistic testing scenarios.
The LLM-based user simulator approach employed by τ-bench creates diverse scenarios that test an agent's ability to follow domain-specific policies while handling dynamic information exchange—a critical capability for real-world applications.
REALM-Bench and Other Emerging Frameworks
Beyond the established leaders, we're seeing specialized testing environments emerge to address specific aspects of agent performance. These frameworks each bring unique approaches to the evaluation landscape.
| Framework | Specialization | Key Strengths | Limitations |
|---|---|---|---|
| REALM-Bench | Knowledge-intensive tasks | Deep factual verification | Limited tool-use assessment |
| WebArena | Web-based interactions | Browser environment simulation | Single-round interactions only |
| SWE-Bench | Software engineering tasks | Code generation & debugging | Narrow domain focus |
| ToolBench | API and tool utilization | Comprehensive API testing | Limited reasoning assessment |
When exploring these specialized frameworks, I rely on PageOn.ai's Deep Search functionality to incorporate the latest updates and findings into my visualizations, ensuring my benchmark comparisons remain current and accurate.
Critical Performance Metrics for Comprehensive Benchmarking
In my experience evaluating AI agents, I've found that a well-rounded assessment requires multiple metric categories. Each provides unique insights into different aspects of agent performance.
Task Completion Metrics
The fundamental measure of an agent's effectiveness is its ability to complete assigned tasks. I track several key indicators in this category:
- Success rate across varying task complexity levels
- Time-to-completion for standard benchmarks
- Resource utilization efficiency (API calls, tokens, compute)
- Error recovery capabilities when facing unexpected inputs
Quality Control Measurements
Beyond simply completing tasks, high-performing agents must deliver quality outputs. The metrics I use to assess quality include:
- Accuracy of information provided
- Consistency across multiple interactions
- Relevance of responses to user queries
- Comprehensiveness of solutions provided
Reasoning and Decision-Making Evaluation
The cognitive capabilities of AI agents represent one of the most challenging aspects to evaluate. I approach this through:
graph TD
A[Reasoning Evaluation] --> B[Chain-of-Thought Analysis]
A --> C[Logical Consistency Checks]
A --> D[Edge Case Handling]
A --> E[Counterfactual Testing]
B --> B1[Step Coherence]
B --> B2[Inference Validity]
C --> C1[Internal Contradictions]
C --> C2[Temporal Consistency]
D --> D1[Boundary Value Testing]
D --> D2[Exception Handling]
E --> E1[Alternative Scenario Exploration]
E --> E2[Decision Robustness]
Ethical AI Validation Metrics
As AI agents become more integrated into critical systems, ethical considerations become paramount. My benchmarking always includes:
- Fairness across demographic groups and scenarios
- Bias detection in agent responses and recommendations
- Explainability of decision-making processes
- Safety guardrails effectiveness
- Privacy preservation capabilities
With PageOn.ai's customizable metric dashboards, I can monitor agent performance across multiple frameworks simultaneously. This gives me a comprehensive view of how different agents perform against various benchmarks, helping identify strengths and weaknesses that might be missed when looking at individual metrics in isolation.
Real-World vs. Simulated Testing Environments
One of the most significant challenges I face in benchmarking AI agents is the "reality gap"—the difference between controlled testing environments and actual deployment scenarios. This gap can lead to misleading performance expectations if not properly addressed.

Strategies for Mimicking Real-World Complexity
To create more realistic testing environments, I implement several approaches:
- Introducing unexpected scenarios that force agents to adapt
- Incorporating ambiguous instructions that require clarification
- Simulating system constraints (latency, token limits, etc.)
- Adding environmental noise and distractions
- Creating diverse user personas with varying communication styles
Multi-Turn Conversation Testing
While many benchmarks focus on single-round interactions, real-world agent usage involves extended conversations. I've found that multi-turn testing reveals capabilities and limitations that remain hidden in simpler evaluations.
As shown in the chart above, while single-turn testing might show higher task completion rates, it dramatically underestimates an agent's capabilities in information retention, context awareness, and error recovery—all critical for real-world applications.
Dynamic Information Exchange Simulation
Real-world agent interactions rarely involve all necessary information being provided upfront. Instead, information is exchanged dynamically throughout a conversation. Advanced testing frameworks like τ-bench excel in this area by simulating realistic information discovery patterns.
sequenceDiagram
participant User
participant Agent
participant Tools
User->>Agent: Initial query (incomplete info)
Agent->>User: Ask clarifying question
User->>Agent: Provide partial information
Agent->>Tools: Query database with available info
Tools->>Agent: Return partial results
Agent->>User: Request specific missing details
User->>Agent: Provide additional context
Agent->>Tools: Complete API call with full parameters
Tools->>Agent: Return complete results
Agent->>User: Deliver comprehensive solution
Using PageOn.ai, I can illustrate these complex interaction patterns between agents and testing environments. This helps my team understand the dynamic nature of real-world agent usage and design more effective testing scenarios.
When working with AI agent tool chains, the complexity of these interactions increases further, as agents must coordinate multiple tools while maintaining context across the entire workflow.
Comparative Analysis: Performance Patterns Across Leading Models
My benchmarking work has revealed fascinating patterns in how different AI models perform across standardized tests. The gap between proprietary and open-source models continues to narrow in some areas while remaining substantial in others.
GPT-4o vs. Open-Source Alternatives
The performance comparison reveals that while GPT-4o maintains a lead across most categories, other models like Claude 3 Opus and Gemini Ultra are competitive in specific areas. Meanwhile, open-source models like Llama 3 70B and Mixtral 8x22B are closing the gap, particularly in knowledge accuracy and instruction following.
When comparing Gemini AI Assistant comparison results against other leading models, we see its particular strengths in knowledge accuracy and reasoning capabilities.
Performance Across Agent Architectures
The architecture used to build an AI agent significantly impacts its performance characteristics. My testing has shown clear patterns in how different approaches perform:
| Architecture | Strengths | Weaknesses | Best Use Cases |
|---|---|---|---|
| ReAct | Reasoning transparency, Step-by-step problem solving | Verbose outputs, Token inefficiency | Complex reasoning tasks, Educational applications |
| Function Calling | API integration, Structured outputs | Limited reasoning visibility, Parameter constraints | Tool automation, Data processing workflows |
| Reflection-based | Self-correction, Error detection | Computational overhead, Latency | High-stakes decisions, Quality-critical applications |
| Multi-agent | Specialized expertise, Debate and refinement | Coordination overhead, Resource intensity | Complex projects, Research assistance |
Domain-Specific Performance Variations
Another critical aspect of my benchmarking work involves understanding how agent performance varies across different domains. This knowledge helps teams select the most appropriate model for their specific use cases.
The radar chart reveals interesting domain-specific strengths. For instance, while GPT-4o excels in creative writing and software development, Claude 3 Opus shows stronger performance in medical assistance and financial analysis. These variations highlight the importance of domain-specific benchmarking when selecting models for particular applications.
PageOn.ai's intuitive charting capabilities make it easy for me to create these comparative visualizations, helping stakeholders quickly grasp the performance landscape across different models and domains.
Implementation Strategies for Effective Benchmarking
Based on my experience implementing benchmarking systems for AI agents, I've developed a structured approach that balances comprehensive evaluation with practical resource constraints.
Establishing Baseline Performance Expectations
Before diving into complex benchmarking, it's essential to establish clear baseline expectations. I typically start with:
- Defining minimum acceptable performance thresholds for critical metrics
- Identifying competitor or industry benchmarks for comparison
- Setting realistic improvement targets based on model capabilities
- Creating a standardized test set that remains consistent across evaluations
Continuous Evaluation Pipeline Development
For organizations serious about AI agent quality, I recommend implementing continuous evaluation pipelines that automatically test new model versions and configurations.
flowchart LR
A[Model Update] --> B[Automated Test Suite]
B --> C{Performance Check}
C -->|Below Threshold| D[Reject & Debug]
C -->|Meets Criteria| E[Candidate for Deployment]
E --> F[A/B Testing]
F --> G{Production Ready?}
G -->|Yes| H[Deploy to Production]
G -->|No| I[Refine Model]
I --> A
D --> I
This pipeline approach ensures that only models meeting or exceeding established benchmarks proceed to production, maintaining consistent quality standards.
Integrating Benchmarking into the Development Lifecycle
Effective benchmarking isn't a one-time activity but an integral part of the AI agent development lifecycle. I integrate benchmarking at multiple stages:
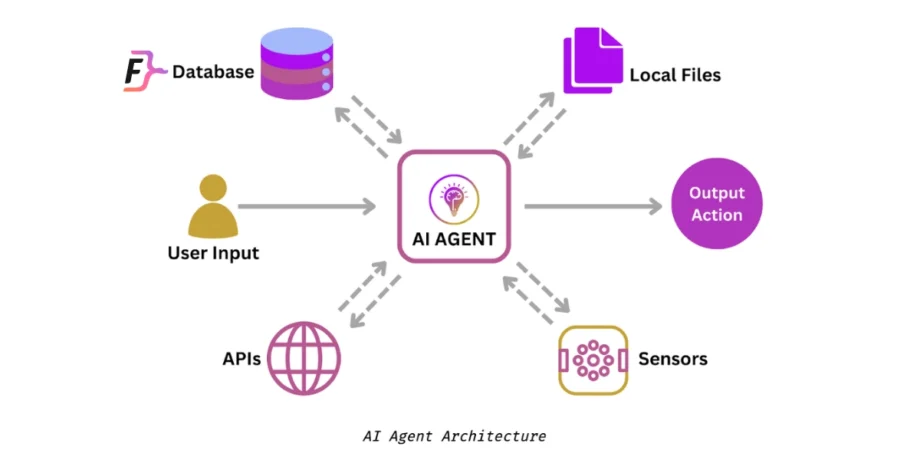
- Design Phase: Benchmark similar existing solutions to establish targets
- Development: Regular testing against standardized benchmarks
- Pre-deployment: Comprehensive evaluation against all relevant frameworks
- Post-deployment: Ongoing monitoring with real-world performance data
- Improvement: Targeted enhancements based on benchmark insights
Federated Testing Approaches
For organizations working with sensitive data or distributed teams, federated testing approaches offer significant advantages. This approach allows benchmarking across decentralized environments while preserving data privacy.
Leveraging open source ai tools can be particularly valuable in implementing federated testing frameworks, as they often provide greater flexibility for customization and deployment across diverse environments.
With PageOn.ai, I can create step-by-step visual workflows of our benchmarking process, making it easier for teams to understand and implement consistent evaluation practices. These visualizations serve as both documentation and training materials, ensuring that everyone follows the established protocols.
Future Directions in AI Agent Benchmarking
As AI agent technology continues to evolve rapidly, the benchmarking landscape must adapt accordingly. I'm particularly excited about several emerging trends that will shape the future of agent evaluation.
Standardized Universal Datasets
One of the most promising developments I see on the horizon is the creation of standardized universal datasets and scoring criteria. These will enable more consistent comparisons across different models and frameworks, addressing a significant pain point in current benchmarking approaches.
Key characteristics of these emerging universal benchmarks include:
- Diverse representation across demographics, cultures, and linguistic patterns
- Standardized scoring methodologies for fairness, robustness, and explainability
- Tiered difficulty levels to assess performance across capability spectrums
- Open governance models to prevent benchmark overfitting
Multi-modal Benchmarking
As agents increasingly work with multiple modalities, benchmarking must evolve to assess performance across text, images, audio, and video. This represents a significant expansion in evaluation complexity.
The chart illustrates the current gap in multi-modal benchmarking coverage and the projected expansion over the next few years. This evolution will be critical as agents increasingly operate across modalities in real-world applications.
Real-time Performance Monitoring
Static benchmarking is giving way to continuous, real-time performance monitoring with automated retraining triggers. This approach allows organizations to maintain optimal agent performance even as usage patterns and requirements evolve.
flowchart TD
A[Deployed Agent] --> B[Real-time Monitoring]
B --> C{Performance Decline?}
C -->|No| D[Continue Monitoring]
C -->|Yes| E[Diagnostic Analysis]
E --> F[Identify Root Cause]
F --> G{Quick Fix Available?}
G -->|Yes| H[Apply Patch]
G -->|No| I[Trigger Retraining]
I --> J[Test New Version]
J --> K{Meets Benchmarks?}
K -->|Yes| L[Deploy Update]
K -->|No| M[Further Development]
M --> J
H --> D
L --> D
Regulatory Compliance Frameworks
As AI regulation matures globally, benchmarking will increasingly incorporate compliance testing against various regulatory frameworks. This will become a critical aspect of agent evaluation, particularly for enterprise applications.
Using PageOn.ai, I can transform these abstract future benchmarking concepts into tangible visual roadmaps that help organizations prepare for coming changes in the evaluation landscape.
Building a Custom Benchmarking Strategy
While standardized benchmarks provide valuable comparative data, I've found that most organizations benefit from developing custom benchmarking strategies tailored to their specific use cases and requirements.
Selecting Appropriate Frameworks
The first step in building a custom strategy is selecting the right combination of benchmarking frameworks. I recommend a tiered approach:
graph TD
A[Framework Selection Process] --> B{Domain-Specific?}
B -->|Yes| C[Select Specialized Frameworks]
B -->|No| D[General-Purpose Frameworks]
C --> E{Multiple Modalities?}
D --> E
E -->|Yes| F[Multi-Modal Benchmarks]
E -->|No| G[Single-Modal Benchmarks]
F --> H{Enterprise Use?}
G --> H
H -->|Yes| I[Add Compliance Testing]
H -->|No| J[Focus on Performance]
I --> K[Custom Test Suite]
J --> K
- Tier 1: Industry-standard benchmarks for broad comparability
- Tier 2: Domain-specific frameworks aligned with your use cases
- Tier 3: Custom scenarios derived from actual user interactions
Balancing Comprehensive Testing with Resource Constraints
Comprehensive benchmarking can be resource-intensive. I help organizations find the right balance through several strategies:
- Prioritizing critical capabilities for in-depth testing
- Using lightweight continuous testing for routine monitoring
- Conducting comprehensive evaluations at key development milestones
- Leveraging cloud resources for computationally intensive benchmarks
Implementing Scalable Evaluation Methodologies
As agent capabilities grow more complex, evaluation methodologies must scale accordingly. I recommend:
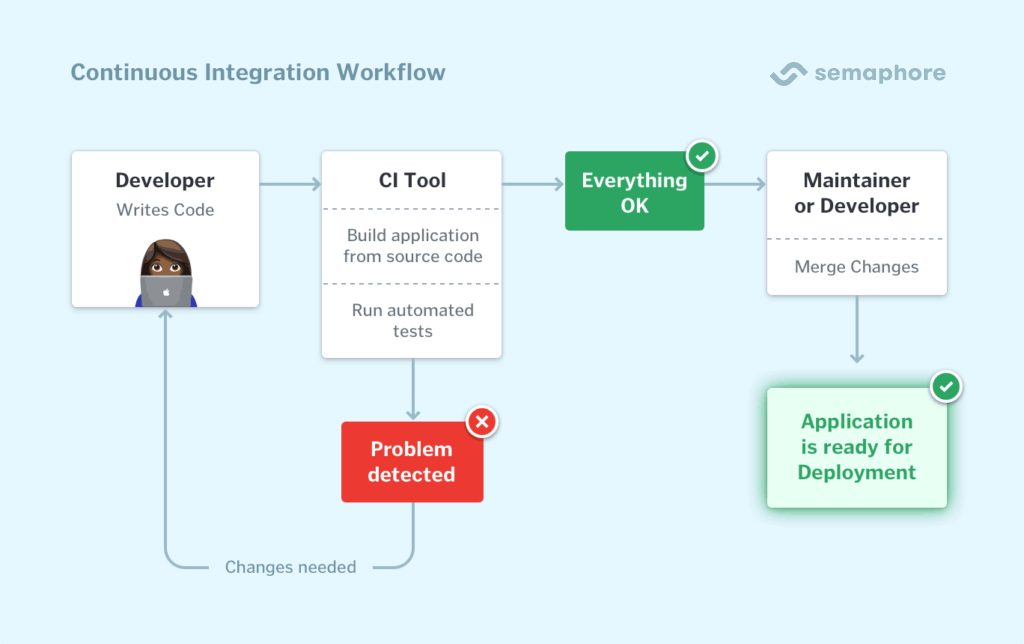
- Building modular testing components that can be combined and reconfigured
- Automating routine evaluation tasks to reduce manual effort
- Implementing progressive difficulty scaling to identify performance boundaries
- Developing hierarchical evaluation approaches that start broad and focus on problem areas
Tools for Automating the Benchmarking Process
Several tools can significantly streamline the benchmarking process:
| Tool Category | Function | Example Tools |
|---|---|---|
| Automated Testing Platforms | Execute test suites at scale | Galileo, AgentQA, Langsmith |
| Data Generation | Create synthetic test data | Synthetic Data Vault, DataGen, SimulatedUsers |
| Evaluation Frameworks | Standardized scoring systems | HELM, Holistic Evaluation of LLMs, TruLens |
| Visualization Tools | Present benchmark results | PageOn.ai, Tableau, PowerBI |
With PageOn.ai's conversation-based design system, I can create personalized benchmarking strategy visualizations that align with specific organizational needs. These visual roadmaps make it easier to communicate complex evaluation plans to stakeholders and ensure alignment across teams.
Transform Your AI Benchmarking with PageOn.ai
Turn complex performance metrics into clear, actionable insights with powerful visualization tools designed for AI professionals.
Start Visualizing Your Benchmarks TodayYou Might Also Like
Transform Any Content into Professional Slides: The Ultimate Conversion Guide
Learn expert techniques for converting documents, presentations, and visual content into professional slides with this comprehensive guide to content format transformation.
Mastering Visual Harmony: Typography and Color Selection for Impactful Presentations
Learn how to create professional presentations through strategic typography and color harmony. Discover font pairing, color theory, and design principles for slides that captivate audiences.
Building Competitive Advantage Through Effective Speaking | Business Communication Strategy
Discover how effective speaking creates measurable competitive advantage in business. Learn strategic communication frameworks, crisis response techniques, and visualization tools for organizational success.
From Status Quo to Solution: Crafting the Perfect Pitch Narrative Arc | PageOn.ai
Learn how to transform your business presentations with powerful status quo to solution narratives. Discover visual storytelling techniques that captivate investors and stakeholders.